Automatically append previous messages to maintain multi-turn context. May increase token usage.
How can I help you today?
高性价比 Gemini 2.5 Flash API:兼具混合推理与极速响应
在 Kie.ai 上部署 Gemini 2.5 Flash API,实现经济高效的混合推理、可控思考以及可扩展的生产级性能。
重磅推出 Google 首款混合推理 LLM —— Gemini 2.5 Flash
Gemini 2.5 Flash 是 Google 首个完全混合推理大语言模型 (LLM),专为在单一模型中结合快速响应生成与可选的内部推理能力而设计。与早期优先考虑即时输出的 Flash 模型不同,Gemini 2.5 Flash 仅在任务需要时才启动推理阶段,从而使同一模型能够同时支持低延迟请求和复杂的多步推理工作负载。这种混合特性通过 Gemini 2.5 Flash API 提供,开发者可以控制何时启用推理功能,从而在生产环境中有效平衡输出质量、延迟与成本。
Google DeepMind Gemini 2.5 Flash API 的核心特性
Gemini 2.5 Flash API:Google 首个混合推理 LLM
Gemini 2.5 Flash API 提供了 Google 首个完全混合推理大语言模型,该模型专为在单个 LLM 中结合快速响应生成与可选的内部推理能力而设计。这种混合设计允许仅在任务需要时应用推理,使 Gemini 2.5 Flash API 无需切换模型或管道,即可支持低延迟请求和复杂的多步推理工作负载。
Gemini 2.5 Flash API:百万级 Token 上下文架构
Gemini 2.5 Flash API 采用百万级 Token 上下文架构,单次请求支持高达 1,048,576 个输入 Token。这使得模型能够将整份文档、庞大的代码库、长对话及多模态数据集作为一个统一的上下文进行推理,而无需依赖过度分块 (Chunking) 或外部记忆系统。通过在上下文中完整保留长程信息,Gemini 2.5 Flash API 能为长上下文工作流提供更连贯的推理、更精准的交叉引用以及更可靠的输出结果。
Gemini 2.5 Flash API:多模态输入与结构化输出
Gemini 2.5 Flash API 支持文本、图像、视频和音频输入,并生成基于文本的结构化输出。借助内置的结构化输出支持,开发者可以设计出能够分析丰富多模态上下文并返回可预测、机器可读响应的工作流。这使得 Gemini 2.5 Flash API 成为兼顾复杂多模态理解与严格输出格式要求的理想选择。
Gemini 2.5 Flash API:内置推理与工具能力
Gemini 2.5 Flash API 原生支持混合推理 (Thinking)、函数调用、代码执行、文件搜索、URL 上下文、搜索增强 (Grounding)、批处理及缓存。凭借这些内置能力,应用仅需单次请求即可将推理与外部工具及数据源结合,从而在生产环境中实现可扩展且成本可控的部署。
Gemini 2.5 Flash API 基准测试结果与模型性能
Gemini 2.5 Flash API 在 Gemini 系列模型中的性能定位
根据内部评估,Gemini 2.5 Flash 在 Gemini 模型家族中拥有明确的定位。相较于 Gemini 2.0 Flash 和 Flash Lite 等早期 Flash 版本,其能力实现了显著跨越,同时有意定位在 Gemini 2.5 Pro 之下。这反映了 Gemini 2.5 Flash API 作为混合推理模型(Hybrid Reasoning Model)的角色——旨在衔接低延迟 Flash 模型与更高能力的推理模型。这标志着 Flash 系列迈出了实质性的一步,而非仅仅是小幅迭代。
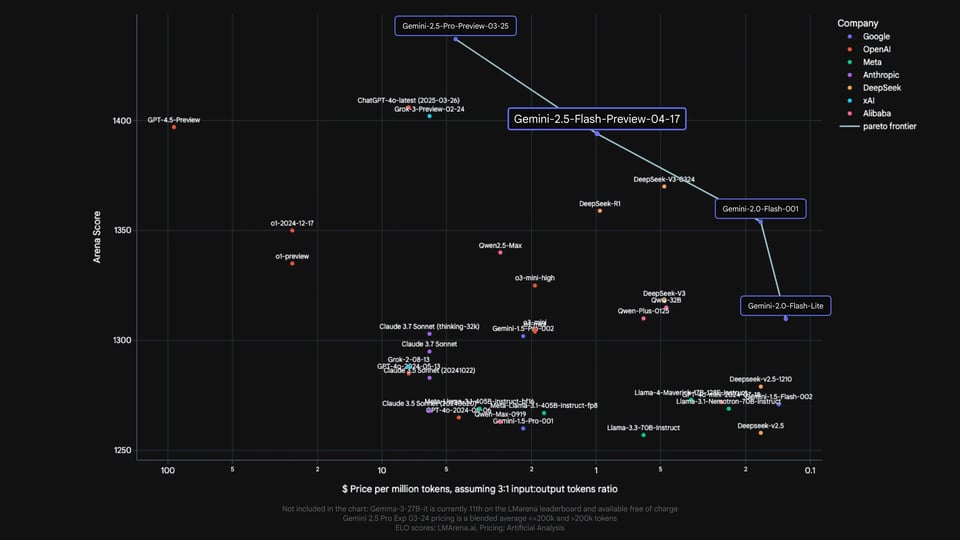
Gemini 2.5 Flash API 与前沿推理模型的基准对比
Google 发布的官方基准测试结果将 Gemini 2.5 Flash 与 OpenAI、Anthropic、xAI 和 DeepSeek 等主流厂商的前沿推理模型进行了横向对比,包括 o4-mini、Claude Sonnet 3.7、Grok 3 和 DeepSeek R1。在数学、科学、编程、多模态理解及长上下文等维度的基准测试中,Gemini 2.5 Flash API 表现极具竞争力,特别是在推理密集型和长上下文评估任务上。以上对比仅供能力参考。原始基准材料中显示的任何价格信息均属 Google 官方发布内容,不代表 Kie.ai 的定价。
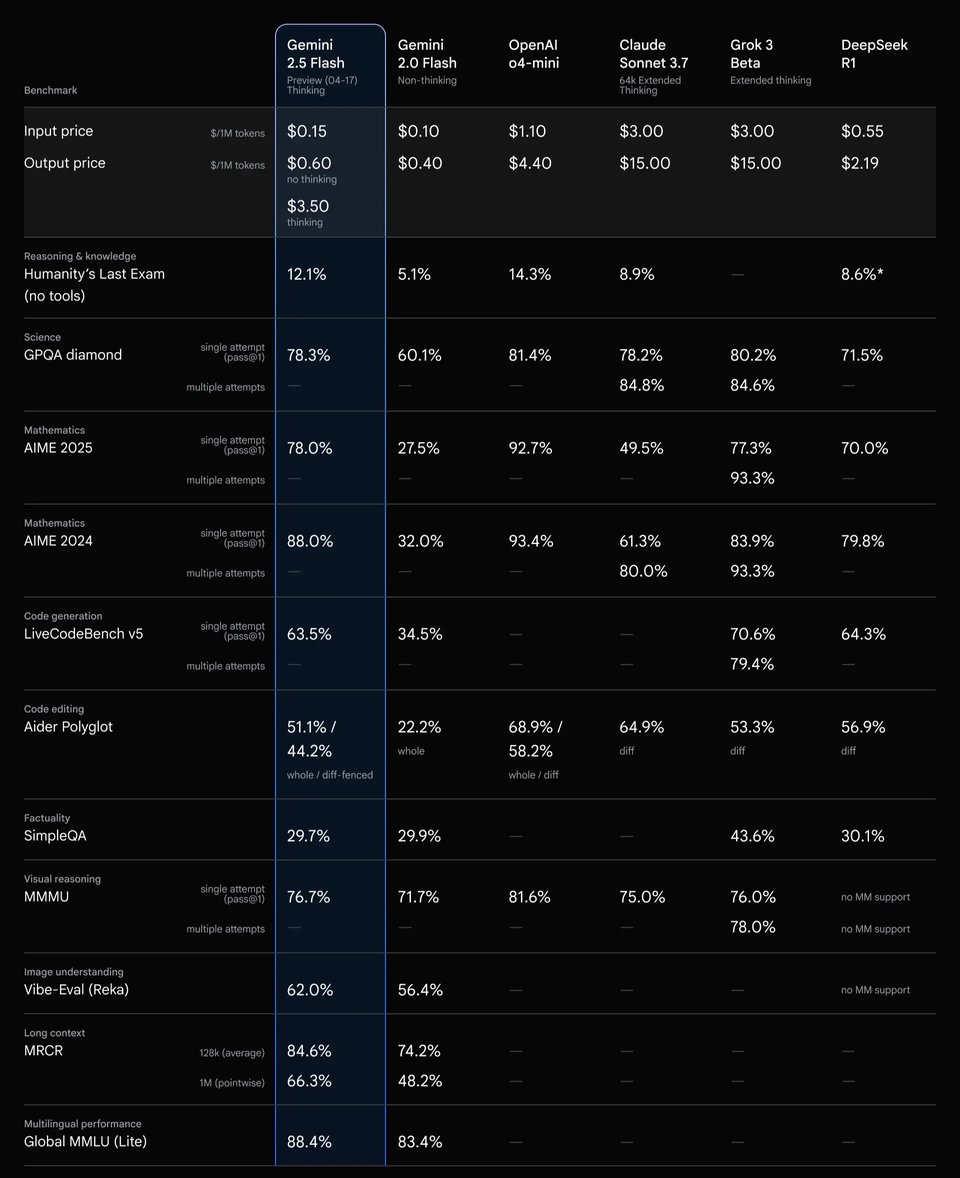
不同思考预算 (Thinking Budgets) 下 Gemini 2.5 Flash API 的推理性能
评测结果显示,Gemini 2.5 Flash API 能将额外的“思考预算”有效转化为更高的推理质量。随着推理预算的增加,模型在科学推理和代码基准测试中的表现稳步提升;其中,中低预算区间的提升最为显著,随后逐渐趋于平稳。这一表现表明,Gemini 2.5 Flash API 能够将投入的推理算力转化为可衡量的质量提升,同时也呈现出边际效益递减的趋势——从而支持在实际应用中实现可控且兼顾成本的推理。
在 Kie.ai 上部署并集成 Gemini 2.5 Flash API
只需简单几步,即可快速上手...
第一步:在 Kie.ai 上注册并创建 Gemini 2.5 Flash API Key
首先在 Kie.ai 上完成注册,并通过开发者仪表盘创建您的 Gemini 2.5 Flash API Key。该密钥用于验证请求,并将 Gemini 2.5 Flash API 的使用量关联到您的账户、项目和环境中。
第二步:选择 Gemini 2.5 Flash API 并配置推理设置
获取 API Key 后,请选择 Gemini 2.5 Flash API 作为目标模型。在此阶段,您可以配置使用 Gemini 2.5 Flash API 时的推理方式,包括开启或关闭推理功能,以及设置合适的“思考预算”以控制推理深度。
第三步:将 Gemini 2.5 Flash API 集成到您的应用工作流中
利用 Gemini 2.5 Flash API 密钥,将 Gemini 2.5 Flash API 集成至后端服务、Agent 工作流或自动化流水线中。Gemini 2.5 Flash API 支持文本、多模态输入及结构化提示词,使应用程序在不改变现有系统架构的情况下即可接入 Gemini 2.5 Flash API。
步骤 4:在生产环境中部署并调优 Gemini 2.5 Flash API
部署您的应用,观察 Gemini 2.5 Flash API 在真实生产负载下的表现。通过微调推理行为、思考预算(Thinking Budgets)和提示词结构,在响应质量与延迟之间找到最佳平衡点。Kie.ai 提供用量可视化功能,帮助团队在扩展 Gemini 2.5 Flash API 部署规模的同时,保持可预期的性能表现。
Gemini 2.5 Flash API 如何根据任务复杂度自适应推理
低推理模式:直接且轻量级的任务
低推理提示词适用于意图清晰、无需多步分析或规划的任务场景。在此模式下,Gemini 2.5 Flash API 专注于快速、直接的内容生成,非常适合翻译、简单事实查询及直接的文本转换。模型应用最少量的内部推理,优先保障低延迟与高效执行。
中推理模式:结构化逻辑与规划
中阶推理提示词通常涉及多重约束、逻辑步骤或轻量级规划。针对此类任务,Gemini 2.5 Flash API 会调用适度的内部推理能力,通过评估条件和对比选项,输出连贯且结构清晰的结果。该模式常被概率问题、日程安排及多条件决策任务触发,在无需深度分析计算的情况下即可提高正确性。
高阶推理模式:多步分析与问题求解
高阶推理提示词要求跨越多个步骤进行持续的内部推理,通常涉及形式逻辑、数学运算或复杂的依赖关系解析。在此模式下,Gemini 2.5 Flash API 会分配更多推理能力将问题拆解,追踪中间状态,并在输出前验证一致性。该层级通常用于工程计算、算法问题求解及代码相关任务,因为这些任务的准确性依赖于深度的结构化推理。
为何选择 Kie.ai 作为您的 Gemini 2.5 Flash API 平台
经济实惠的 Gemini 2.5 Flash API 定价方案
Kie.ai 提供高性价比的 Gemini 2.5 Flash API 接入服务,让混合推理能力在实验与生产环境中都触手可及。我们的定价结构专为大规模工作负载设计,在杜绝不必要的额外开销的同时,助力团队充满信心地扩展 Gemini 2.5 Flash API 的应用规模。
详尽的 Gemini 2.5 Flash API 文档
Kie.ai 为 Gemini 2.5 Flash API 提供了结构清晰、内容详尽的开发者文档,涵盖身份验证、推理机制、思考预算 (Thinking Budgets)、长上下文使用及部署流程。这份全面的指南有助于开发者高效集成 Gemini 2.5 Flash API,无需依赖零散的外部参考资料。
全天候 Gemini 2.5 Flash API 技术支持
Kie.ai 为 Gemini 2.5 Flash API 用户提供全天候服务。无论您是在进行集成测试、部署生产环境,还是排查异常行为,我们的 7x24 小时支持都能确保基于 Gemini 2.5 Flash API 的应用始终可靠运行。