Click to upload or drag and drop
Supported formats: MPEG, WAV, X-WAV, AAC, MP4, OGG Maximum file size: 200MB
URL of the audio file to transcribe
Language code of the audio
Tag audio events like laughter, applause, etc.
Whether to annotate who is speaking
A configurable parameter. Defaults to true in the Playground.
Complete guide to using
ElevenLabs语音转文本API
通过ElevenLabs Scribe API,将音频转化为精准文本,支持99种语言、讲者分离、音频事件标签,API定价实惠,专为开发者优化。
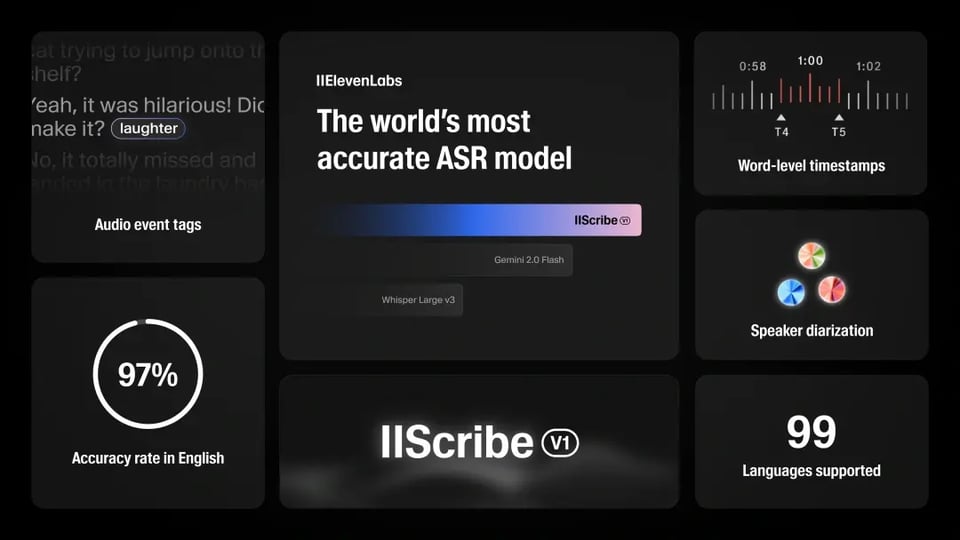
ElevenLabs Scribe v1 API:以卓越精度将语音转录为文本
ElevenLabs语音转文本API旨在将语音音频转换为精准、清晰且结构化的文本,具有行业领先的精度。由ElevenLabs Scribe v1模型驱动,能够应对背景噪音、多讲者和不同口音等复杂音频环境挑战。开发者可轻松将音频转录为99种语言的文本,适用于应用程序、媒体和企业工作流。
ElevenLabs Scribe v1 API 的强大功能
支持99种语言的语音识别功能
ElevenLabs语音转文本API支持99种语言的自动转录,包括塞尔维亚语和马拉雅拉姆语等较少使用的语言。无论您是在开发多语言应用程序、转录国际销售电话,还是为全球媒体制作字幕,Scribe ASR模型都能确保在各种口音和方言中保持高准确度,无需手动切换语言。
行业领先的准确度
ElevenLabs语音转文本API在准确度上处于行业领先地位,按照FLEURS基准,英语的单词错误率低至3.3%,意大利语为1.3%。它在嘈杂环境、各种口音和自然语音中表现优异,非常适合用于播客、访谈或会议的音频转录。
字符级时间戳,精确对齐
实时预览,精确显示每个单词的发音时刻。通过字符级时间戳,开发者可精确捕捉每个单词的发音时刻。此功能对于字幕、隐形字幕以及时间同步的转录至关重要。通过使用ElevenLabs Scribe API,您可以实现精准对齐的音频转文本,为用户提供更加流畅的阅读与观看体验。
支持多讲者音频的讲者分离功能
ElevenLabs 语音转文本 API 可在单段录音中识别最多 32 位讲者,并为每位讲者进行精准标注。该功能非常适用于会议或座谈会的转录,确保每个讲者的身份标注清晰。开发者可利用讲者分离生成结构化、可搜索的转录文本,提高协作或媒体项目的效率。
音频事件标签,丰富转录内容
ElevenLabs Scribe API 不仅能转录语音,还可标记笑声、掌声等非语言声音,为音频转文本结果增添更多上下文。该音频事件标签功能为转录提供更多背景信息,使内容更为生动。语音转文本 API 输出结构化 JSON,便于集成到创意工作流程。
ElevenLabs 语音转文本 API 与其他 ASR 模型对比
ElevenLabs 语音转文本 API 采用 Scribe v1 模型,在音频转文本领域处于领先地位,具备卓越的准确性、支持 99 种语言,并提供讲者分离等高级能力。与 OpenAI Whisper、Google Cloud 语音转文本和 AWS Transcribe 相比,它在应对真实世界音频挑战方面表现更优。虽然 OpenAI Whisper 在成本效益方面表现出色,但缺少原生讲者分离;Google Cloud 虽然提供强大的流式转录能力,但整体成本更高;AWS 虽然具备合规优势,但在多语言准确性方面不及 ElevenLabs。
| 功能 | ElevenLabs Scribe v1 | OpenAI Whisper | Google Cloud 语音转文本 | AWS Transcribe |
|---|---|---|---|---|
| WER (English) | 3.3% (FLEURS) | 7.7% (Indonesian) | Higher in accents | Higher in noise |
| Languages | 99, auto-detection | ~99, translation | 125+, ecosystem | 100+, streaming |
| Diarization | Up to 32 speakers | None (add-ons) | Limited precision | Custom setup |
| Event Tagging | Applause and various non-verbal cues | Not supported | Limited | Not supported |
| Latency | Low for optimized formats | Hardware-dependent | Real-time streaming | Streaming-focused |
为何选择 Kie.ai 提供的 ElevenLabs 语音转文本 API
实惠的语音转文本 API 定价
Kie.ai 通过灵活的积分计费系统提供 ElevenLabs 语音转文本 API,开发者根据使用量付费,轻松进行测试、扩展和功能集成。与 ElevenLabs 官方方案及其他服务商(如 Fal)相比,Kie.ai 以更低成本提供同样高质量的语音识别服务。
全面的 API 文档和开发者支持
借助详细的 ElevenLabs API 文档,集成过程变得更加轻松。Kie.ai 提供清晰的示例、代码片段和技术指南,帮助开发者迅速入门。专门的支持渠道确保顺利接入并高效解决问题。
创新、可靠并具备可扩展性的基础设施
Kie.ai 提供 99.9% 高可用性并支持高并发,确保语音转文本 API 无论在单用户应用还是企业级工作负载下都能稳定运行。无论是处理简短语音记录还是大规模会议转录,开发者可以依赖其稳定和高效的表现。
如何在 Kie.ai 平台上集成 ElevenLabs STT API
第一步:获取语音转文本 API 密钥
在 Kie.ai 注册账号以获取 API 密钥。该密钥可安全地访问 ElevenLabs 语音转文本 API,用于身份验证并发起调用。
第二步:创建转录任务
发送请求到任务接口,模型设置为 "elevenlabs/speech-to-text"。提供音频文件 URL 和可选参数,如 language_code、tag_audio_events 或 diarize,以便根据您的需求定制语音识别API。
第三步:获取转录结果
检查任务状态或使用 callBackUrl 自动获取转录结果。ElevenLabs Scribe API 返回结构化的 JSON 输出,可与应用程序、字幕或企业工作流集成使用 STT API。