Automatically append previous messages to maintain multi-turn context. May increase token usage.
How can I help you today?
Complete guide to using
Kie.ai 现已提供高性价比 Claude Opus 4.6 API
在 Kie.ai 获取 Anthropic Claude Opus 4.6 API,以更低成本部署编程、推理及长上下文工作流。

Anthropic Claude Opus 4.6 API 新特性
Claude Opus 4.6 API:更强劲的编程、调试与代码审查能力
Claude Opus 4.6 API 带来了软件工程性能的显著升级。它在处理编程任务时规划更周全,调试准确性更高,并能在更大规模、更复杂的代码库中执行可靠的代码审查。相比早期 Opus 模型,Claude Opus 4.6 API 更擅长捕捉错误、重新审视推理逻辑,并在多步骤开发工作流中持续保持高质量输出。
Claude Opus 4.6 API 配备 1M Token 上下文窗口
Claude Opus 4.6 API 最重大的更新之一是推出了 1M Token 上下文窗口(Beta 版)。这为 Claude Opus 4.6 API 在长文档处理、大范围上下文检索以及针对密集输入的扩展推理方面提供了更强有力的支持。该功能旨在减少上下文漂移,并显著提升在海量文本中追踪关键信息时的性能。
Claude Opus 4.6 API 新特性:自适应思考、推理力度控制与上下文压缩
Claude Opus 4.6 API 新增多项控制功能,使其更贴合生产环境需求。借助“自适应思考”,Claude Opus 4.6 API 能在必要时进行更深度的推理;“推理力度控制”赋予开发者更高灵活性,在智能水平、延迟和成本之间找到最佳平衡;“上下文压缩”则通过在达到上限前摘要旧内容,进一步助力 Claude Opus 4.6 API 支持长对话及智能体工作流。
128k Token 输出扩展了 Claude Opus 4.6 API 对更大规模任务的支持
Claude Opus 4.6 API 支持最高 128k Token 的输出,使其更适合需要在单次运行中生成大规模响应的任务。这一特性在长文生成、大规模代码转换、结构化文档输出等场景下尤为实用,避免了以往繁琐的拆分请求流程。得益于更高的输出上限,Claude Opus 4.6 API 为需要完整、长篇幅输出的应用提供了更具实操性的解决方案。
如何在 Kie.ai 上以高性价比部署 Claude Opus 4.6 API
只需简单几步,即可快速上手我们的产品...
注册 Kie.ai 账号,获取 Claude Opus 4.6 API Key
首先注册 Kie.ai 账号以获取 Claude Opus 4.6 API 访问权限。注册后,您可在控制台生成 API Key 并准备集成环境。这为您测试请求、完成 API 鉴权以及在对开发者更友好的工作流中构建 Claude Opus 4.6 API 应用提供了直接起点。
在 Playground 中免费试用 Claude Opus 4.6 API
在正式开发前,利用 Playground 免费试用 Claude Opus 4.6 API。这是评估响应质量、探索 Prompt 行为,以及了解模型在编程、长上下文(Long-context)、推理或 Agent 类任务中表现的最快途径。这有助于团队尽早验证业务场景,同时了解 Kie.ai 提供的 Claude Opus 4.6 API 实惠价格。
将 Claude Opus 4.6 API 集成到您的应用中
在 Playground 完成测试后,即可将 Claude Opus 4.6 API 对接到您的应用或工作流中。利用 API Key 从后端、工具链或内部平台发起请求,将模型能力植入实际业务逻辑。此步骤将把您在 Kie.ai 上的初步实验转化为聊天、编程、文档处理或 Agent 等场景的落地应用。
为生产环境配置 Claude Opus 4.6 API
基础集成跑通后,请针对生产环境进行优化。您需要调整请求结构,打磨提示词以提升输出稳定性,并结合任务复杂度、延迟要求及成本预期来优化调用策略。这能让 Claude Opus 4.6 API 更适用于长期部署,而非仅限于简单的一次性测试。
在 Kie.ai 上规模化部署 Claude Opus 4.6 API
工作流验证通过后,即可全面部署 Claude Opus 4.6 API。此时,团队通常会将应用扩展至面向客户的产品、内部自动化系统、研究工作流或代码相关工具中。Kie.ai 让从测试、集成到部署的路径更加顺畅,助您在实际生产场景中直观评估 Claude Opus 4.6 API 的价格优势。
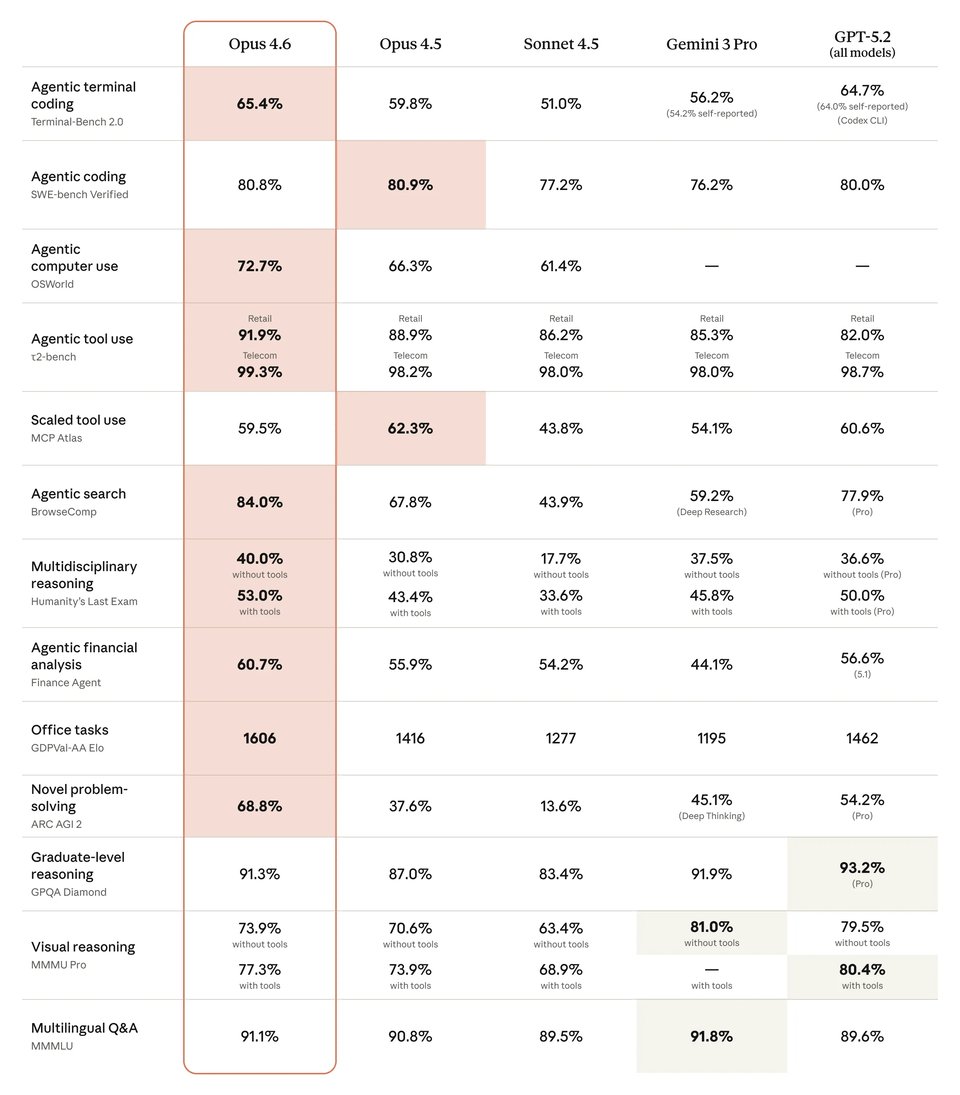
Claude Opus 4.6 与 Gemini 3.1 Pro、GPT-5.4 及其他 Claude 模型的对比
与 Gemini 3.1 Pro、GPT-5.4 及早期 Claude 模型相比,Claude Opus 4.6 在代码编程、计算机使用、搜索及高级推理方面展现出强劲的基准测试表现。如下方对比所示,Claude Opus 4.6 在多个高价值工作流基准测试中,明显领先于 Claude Opus 4.5、Claude Sonnet 4.5 和 Gemini 3.1 Pro;而在终端编码、计算机使用及研究生级推理等领域,GPT-5.4 依然保持着极高的竞争力。这使得 Claude Opus 4.6 成为团队在评估智能体任务(Agentic tasks)及生产级知识型工作时的理想模型选择。
| 基准测试 | Claude Opus 4.6 | Claude Opus 4.5 | Claude Sonnet 4.5 | Gemini 3.1 Pro | GPT-5.4 |
|---|---|---|---|---|---|
| Agentic terminal coding | 65.40% | 59.80% | 51.00% | 68.50% | 75.10% |
| Agentic computer use | 72.70% | 66.30% | 61.40% | — | 75.00% |
| Agentic search | 84.00% | 67.80% | 43.90% | 85.90% | 82.70% |
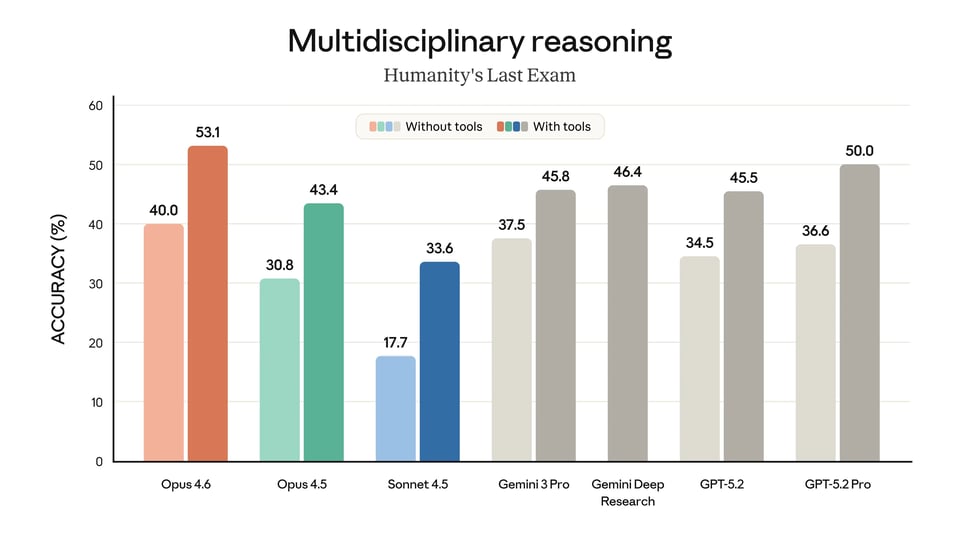
| Multidisciplinary reasoning (no tools) | 40.00% | 30.80% | 17.70% | 44.70% | 39.80% |
| Multidisciplinary reasoning (with tools) | 53.00% | 43.40% | 33.60% | — | 52.10% |
| Graduate-level reasoning | 91.30% | 87.00% | 83.40% | 94.30% | 92.80% |