Automatically append previous messages to maintain multi-turn context. May increase token usage.
How can I help you today?
Affordable Gemini 2.5 Flash API for Hybrid Reasoning and Fast Inference
Deploy the Gemini 2.5 Flash API on Kie.ai for cost-efficient hybrid reasoning, controllable thinking, and scalable production performance.
Introducing Google First Hybrid Reasoning LLM —— Gemini 2.5 Flash
Gemini 2.5 Flash is Google’s first fully hybrid reasoning large language model (LLM), designed to combine fast response generation with optional internal reasoning within a single model. Unlike earlier Flash models that prioritize immediate output, Gemini 2.5 Flash can engage a reasoning phase only when a task requires it, allowing the same model to support both low-latency requests and complex, multi-step reasoning workloads. This hybrid behavior is exposed through the Gemini 2.5 Flash API, where developers can control when reasoning is applied and manage the trade-off between output quality, latency, and cost in production environments.
Key Features of Google DeepMind's Gemini 2.5 Flash API
Google’s First Hybrid Reasoning LLM in Gemini 2.5 Flash API
The Gemini 2.5 Flash API exposes Google’s first fully hybrid reasoning large language model, designed to combine fast response generation with optional internal reasoning within a single LLM. This hybrid design allows reasoning to be applied only when a task requires it, enabling Gemini 2.5 Flash API to support both low-latency requests and complex, multi-step reasoning workloads without switching models or pipelines.
Million-Token Context Architecture with Gemini 2.5 Flash API
Gemini 2.5 Flash API is built around a million-token context architecture, supporting up to 1,048,576 input tokens in a single request. This enables the model to reason over entire documents, large codebases, long conversations, and multimodal datasets as a unified context, rather than relying on aggressive chunking or external memory systems. By keeping long-range information fully in-context, Gemini 2.5 Flash API delivers more consistent reasoning, stronger cross-reference accuracy, and more reliable outputs for long-context workflows.
Multimodal Inputs and Structured Outputs in Gemini 2.5 Flash API
The Gemini 2.5 Flash API accepts text, image, video, and audio inputs, while producing structured, text-based outputs. With built-in support for structured outputs, developers can design workflows that analyze rich multimodal context and return predictable, machine-readable responses. This makes Gemini 2.5 Flash API well suited for applications that require strict output formats alongside complex multimodal understanding.
Built-In Reasoning and Tooling Capabilities in Gemini 2.5 Flash API
Gemini 2.5 Flash API includes native support for hybrid reasoning (thinking), function calling, code execution, file search, URL context, search grounding, batch processing, and caching. These built-in capabilities allow applications to combine reasoning with external tools and data sources in a single request, enabling scalable, cost-controlled deployments across production environments.
Gemini 2.5 Flash API Benchmark Results and Model Performance
Gemini 2.5 Flash API Performance Within the Gemini Model Lineup
Across internal evaluations, Gemini 2.5 Flash occupies a clearly defined position within the Gemini model lineup. It delivers a substantial capability increase over earlier Flash variants, including Gemini 2.0 Flash and Flash Lite, while remaining intentionally positioned below Gemini 2.5 Pro. This reflects the role of Gemini 2.5 Flash API as a hybrid reasoning model designed to bridge low-latency Flash models and higher-capacity reasoning models, representing a meaningful step forward within the Flash family rather than a minor incremental update.
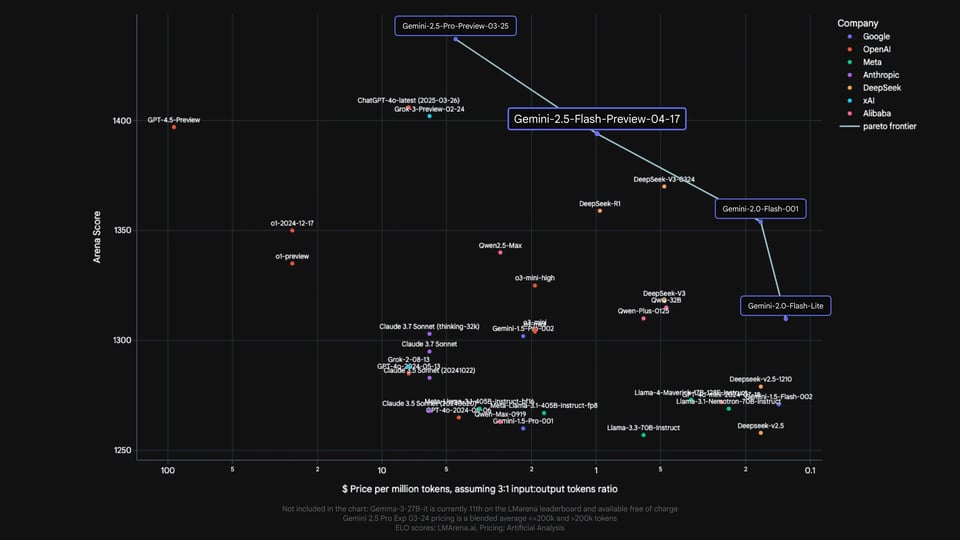
Gemini 2.5 Flash API Benchmarks Compared with Frontier Reasoning Models
Official benchmark results published by Google evaluate Gemini 2.5 Flash alongside widely used frontier reasoning models from OpenAI, Anthropic, xAI, and DeepSeek, including models such as o4-mini, Claude Sonnet 3.7, Grok 3, and DeepSeek R1. Across mathematics, science, coding, multimodal understanding, and long-context benchmarks, Gemini 2.5 Flash API demonstrates competitive performance relative to these models, particularly on reasoning-heavy and long-context evaluations. These comparisons are provided for capability reference only. Any pricing information shown in the original benchmark materials is part of Google’s publication and does not represent pricing on Kie.ai.
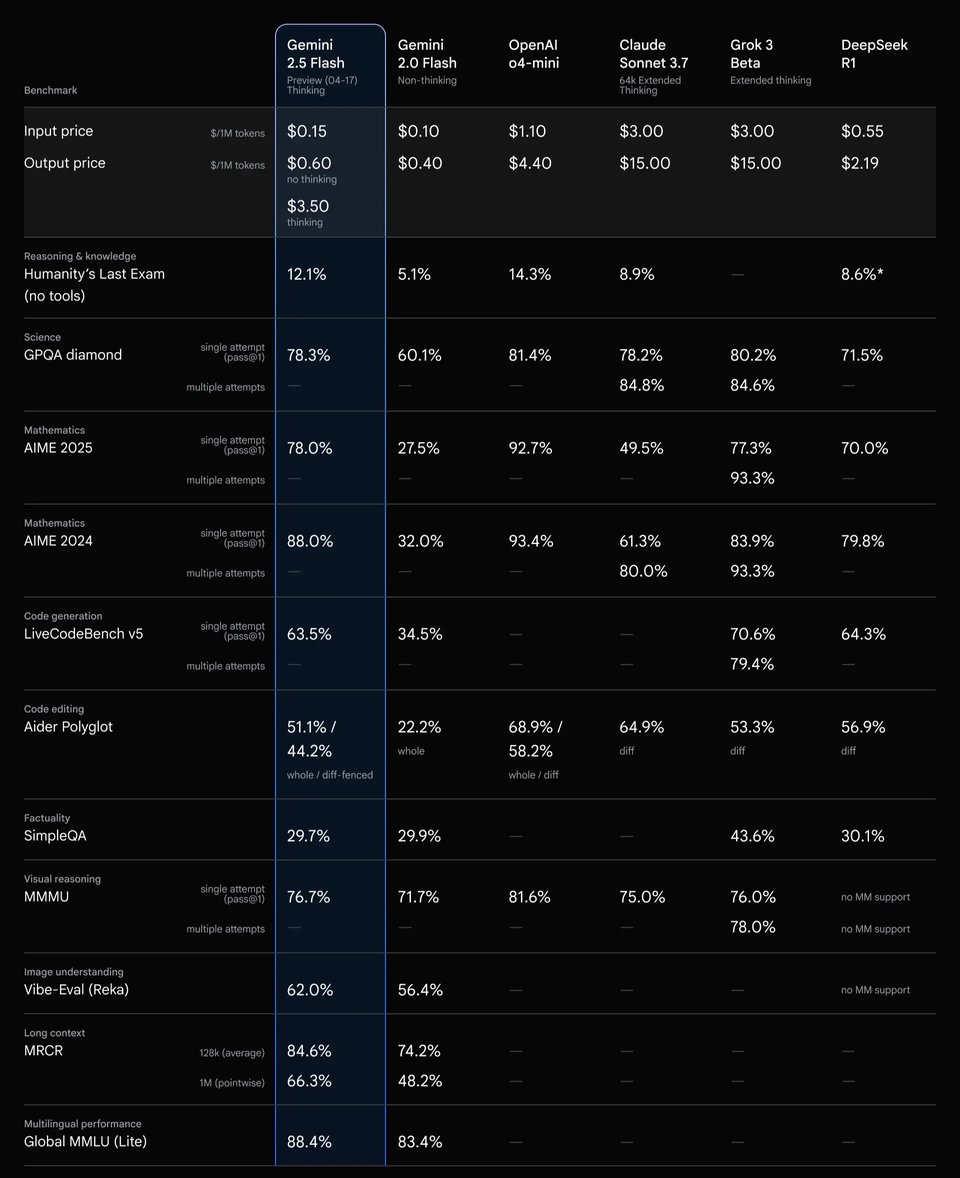
Gemini 2.5 Flash API Reasoning Performance with Different Thinking Budgets
Evaluation results also show how Gemini 2.5 Flash API converts additional thinking budget into improved reasoning quality. As more reasoning budget is allocated, performance increases steadily on scientific reasoning and coding benchmarks, with the most significant gains appearing at low to mid budget ranges before gradually plateauing. This behavior indicates that Gemini 2.5 Flash API can effectively translate additional reasoning computation into measurable quality improvements, while also exhibiting diminishing returns beyond certain thresholds—supporting controlled, budget-aware reasoning in real-world applications.
Deployment and Integration of Gemini 2.5 Flash API on Kie.ai
Get started with our product in just a few simple steps...
Step 1: Register on Kie.ai and Create a Gemini 2.5 Flash API Key
Start by registering on Kie.ai and creating your Gemini 2.5 Flash API key from the developer dashboard. The Gemini 2.5 Flash API key is required for authenticating requests and linking Gemini 2.5 Flash API usage to your account, projects, and environments.
Step 2: Select the Gemini 2.5 Flash API and Configure Reasoning Settings
Once your Gemini 2.5 Flash API key is available, select Gemini 2.5 Flash API as the target model. At this stage, you can configure how reasoning is applied when using Gemini 2.5 Flash API, including enabling or disabling reasoning and setting an appropriate thinking budget to control reasoning depth.
Step 3: Integrate Gemini 2.5 Flash API into Your Application Workflow
Integrate Gemini 2.5 Flash API into your backend service, agent workflow, or automation pipeline using your Gemini 2.5 Flash API key. Gemini 2.5 Flash API supports text and multimodal inputs as well as structured prompts, allowing applications to adopt Gemini 2.5 Flash API without changes to existing system architecture.
Step 4: Deploy and Optimize Gemini 2.5 Flash API in Production
Deploy your application and observe how Gemini 2.5 Flash API performs under real production workloads. Fine-tune reasoning behavior, thinking budgets, and prompt structure to achieve the desired balance between response quality and latency. Kie.ai provides usage visibility to help teams scale Gemini 2.5 Flash API deployments while maintaining predictable performance.
How Gemini 2.5 Flash API Adapts Reasoning to Task Complexity
Low-Reasoning Mode: Direct and Lightweight Tasks
Low-reasoning prompts are tasks where the intent is clear and the response does not require multi-step analysis or planning. In this mode, Gemini 2.5 Flash API focuses on fast, direct generation, making it suitable for translations, simple factual queries, and straightforward text transformations. The model applies minimal internal reasoning, prioritizing low latency and efficient execution.
Medium-Reasoning Mode: Structured Logic and Planning
Medium-reasoning prompts involve multiple constraints, logical steps, or light planning. For these tasks, Gemini 2.5 Flash API engages a moderate level of internal reasoning to evaluate conditions, compare options, and produce coherent, structured outputs. This mode is commonly triggered by probability problems, scheduling scenarios, and multi-condition decision tasks, where reasoning improves correctness without requiring deep analytical computation.
High-Reasoning Mode: Multi-Step Analysis and Problem Solving
High-reasoning prompts require sustained internal reasoning across many steps, often involving formal logic, mathematics, or complex dependency resolution. In this mode, Gemini 2.5 Flash API allocates a larger portion of its reasoning capacity to break down the problem, track intermediate states, and verify consistency before producing a result. This level is typically used for engineering calculations, algorithmic problem solving, and code-related tasks where accuracy depends on deep, structured reasoning.
Why Choose Kie.ai as Your Gemini 2.5 Flash API Platform
Affordable Gemini 2.5 Flash API Pricing
Kie.ai offers cost-effective access to Gemini 2.5 Flash API, making hybrid reasoning capabilities affordable for both experimentation and production use. The pricing structure is designed to support high-volume workloads without introducing unnecessary cost overhead, allowing teams to scale Gemini 2.5 Flash API usage confidently.
Comprehensive Gemini 2.5 Flash API Documentation
Gemini 2.5 Flash API on Kie.ai is supported by clear, well-structured developer documentation that covers authentication, reasoning behavior, thinking budgets, long-context usage, and deployment workflows. This comprehensive documentation helps developers integrate Gemini 2.5 Flash API efficiently without relying on fragmented or external references.
24/7 Gemini 2.5 Flash API Support
Kie.ai provides round-the-clock support for Gemini 2.5 Flash API users. Whether you are testing integrations, deploying to production, or troubleshooting unexpected behavior, 24/7 assistance ensures that Gemini 2.5 Flash API–powered applications remain reliable and operational at all times.