Automatically append previous messages to maintain multi-turn context. May increase token usage.
How can I help you today?
API Gemini 2.5 Flash abordable pour le raisonnement hybride et l'inférence rapide
Déployez l'API Gemini 2.5 Flash sur Kie.ai pour bénéficier d'un raisonnement hybride économique, d'une réflexion contrôlable et de performances de production à l'échelle.
Découvrez le premier LLM à raisonnement hybride de Google : Gemini 2.5 Flash
Gemini 2.5 Flash est le premier grand modèle de langage (LLM) à raisonnement entièrement hybride de Google, conçu pour combiner une génération de réponse rapide avec une capacité de raisonnement interne optionnelle au sein d'un même modèle. Contrairement aux précédents modèles Flash axés sur l'instantanéité, Gemini 2.5 Flash peut activer une phase de raisonnement uniquement si la tâche le nécessite, permettant à un seul modèle de prendre en charge à la fois les requêtes à faible latence et les charges de travail complexes de raisonnement en plusieurs étapes. Ce comportement hybride est accessible via l'API Gemini 2.5 Flash, permettant aux développeurs de contrôler l'activation du raisonnement et de gérer le compromis entre qualité, latence et coût en production.
Fonctionnalités clés de Gemini 2.5 Flash API de Google DeepMind
Le premier LLM à raisonnement hybride de Google dans l'API Gemini 2.5 Flash
L'API Gemini 2.5 Flash donne accès au premier grand modèle de langage (LLM) à raisonnement entièrement hybride de Google. Conçu pour allier rapidité de génération et raisonnement interne optionnel au sein d'un même modèle, ce design hybride permet d'activer le raisonnement uniquement lorsque la tâche l'exige. Ainsi, l'API Gemini 2.5 Flash prend en charge aussi bien les requêtes à faible latence que les charges de travail complexes nécessitant un raisonnement en plusieurs étapes, sans avoir à changer de modèle ou de pipeline.
Architecture à fenêtre contextuelle d'un million de tokens avec l'API Gemini 2.5 Flash
L'API Gemini 2.5 Flash repose sur une architecture à un million de tokens, prenant en charge jusqu'à 1 048 576 tokens par requête. Cela permet au modèle d'analyser des documents entiers, de vastes bases de code, de longues conversations et des jeux de données multimodaux au sein d'un contexte unifié, sans recourir à une fragmentation excessive ni à des systèmes de mémoire externes. En conservant l'intégralité des informations en contexte, Gemini 2.5 Flash garantit un raisonnement plus cohérent, des références croisées plus précises et des résultats plus fiables pour les flux de travail à contexte étendu.
Entrées multimodales et sorties structurées avec l'API Gemini 2.5 Flash
L'API Gemini 2.5 Flash accepte des entrées sous forme de texte, d'image, de vidéo et d'audio, tout en générant des sorties textuelles structurées. Grâce à cette prise en charge native, les développeurs peuvent concevoir des flux de travail analysant des contextes multimodaux riches pour renvoyer des réponses prévisibles et lisibles par une machine. L'API Gemini 2.5 Flash est ainsi particulièrement adaptée aux applications exigeant à la fois une compréhension multimodale complexe et des formats de sortie stricts.
Capacités de raisonnement et outils intégrés à l'API Gemini 2.5 Flash
L'API Gemini 2.5 Flash intègre nativement le raisonnement hybride (thinking), l'appel de fonction, l'exécution de code, la recherche de fichiers, le contexte via URL, l'ancrage dans la recherche (Search Grounding), le traitement par lots et la mise en cache. Ces fonctionnalités intégrées permettent aux applications de combiner raisonnement, outils externes et sources de données en une seule requête, facilitant ainsi des déploiements en production évolutifs et à coûts maîtrisés.
Résultats des benchmarks et performances de l'API Gemini 2.5 Flash
Performances de Gemini 2.5 Flash API au sein de la gamme Gemini
D'après les évaluations internes, Gemini 2.5 Flash occupe une position clairement définie au sein de la gamme Gemini. Il marque une nette progression par rapport aux variantes Flash précédentes, comme Gemini 2.0 Flash et Flash Lite, tout en restant intentionnellement positionné en dessous de Gemini 2.5 Pro. Ce positionnement illustre le rôle de Gemini 2.5 Flash API en tant que modèle de raisonnement hybride, conçu pour faire la jonction entre les modèles Flash à faible latence et les modèles de raisonnement à haute capacité. Il constitue ainsi une avancée significative au sein de la famille Flash, bien plus qu'une simple mise à jour.
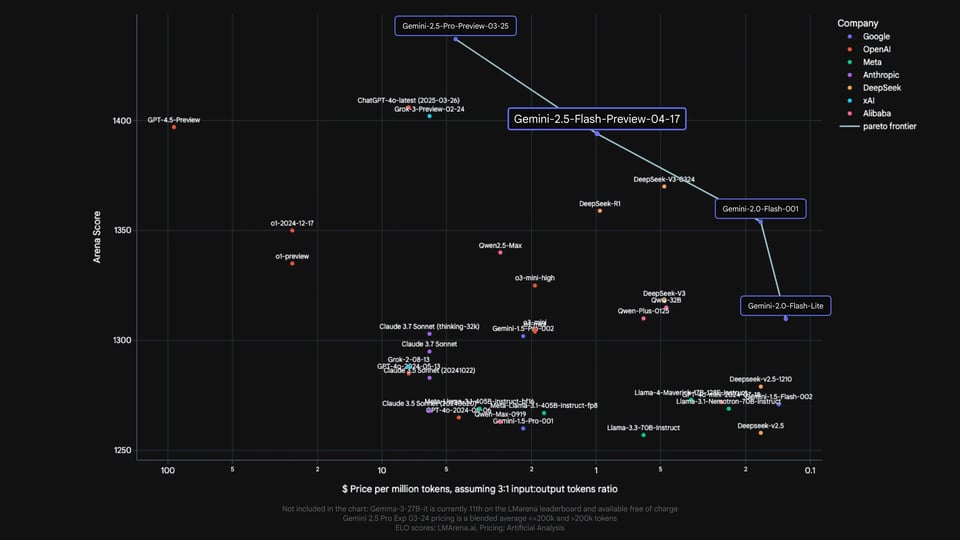
Comparatif des performances de Gemini 2.5 Flash API face aux modèles de raisonnement de pointe
Les résultats officiels publiés par Google comparent Gemini 2.5 Flash à des modèles de raisonnement de pointe largement utilisés, issus d'OpenAI, Anthropic, xAI et DeepSeek, notamment o4-mini, Claude Sonnet 3.7, Grok 3 et DeepSeek R1. En mathématiques, sciences, programmation, compréhension multimodale et gestion de longs contextes, Gemini 2.5 Flash API affiche des performances compétitives par rapport à ces modèles, en particulier sur les évaluations axées sur le raisonnement et les longues fenêtres de contexte. Ces comparaisons sont fournies à titre indicatif uniquement. Les prix indiqués dans les documents originaux font partie de la publication de Google et ne reflètent pas la tarification sur Kie.ai.
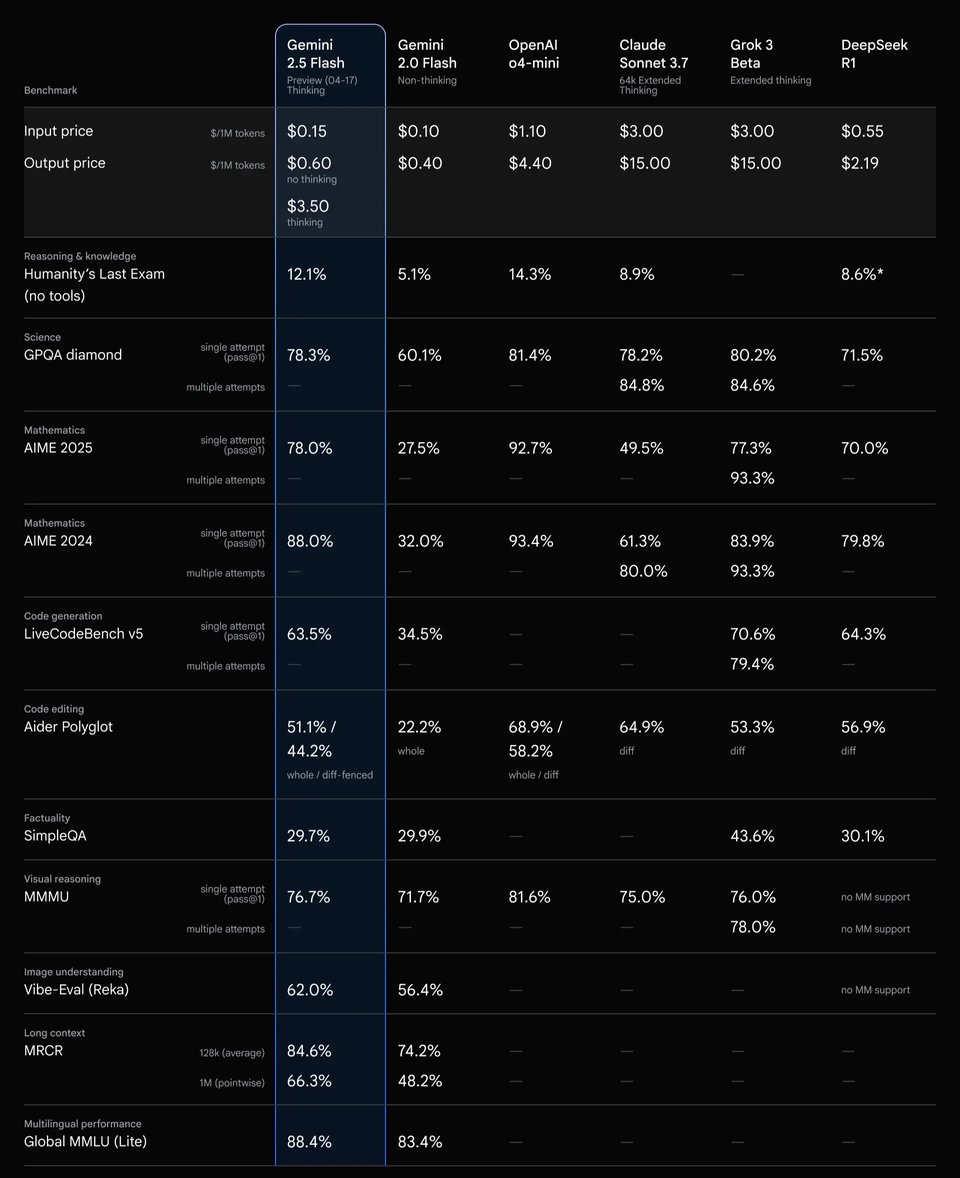
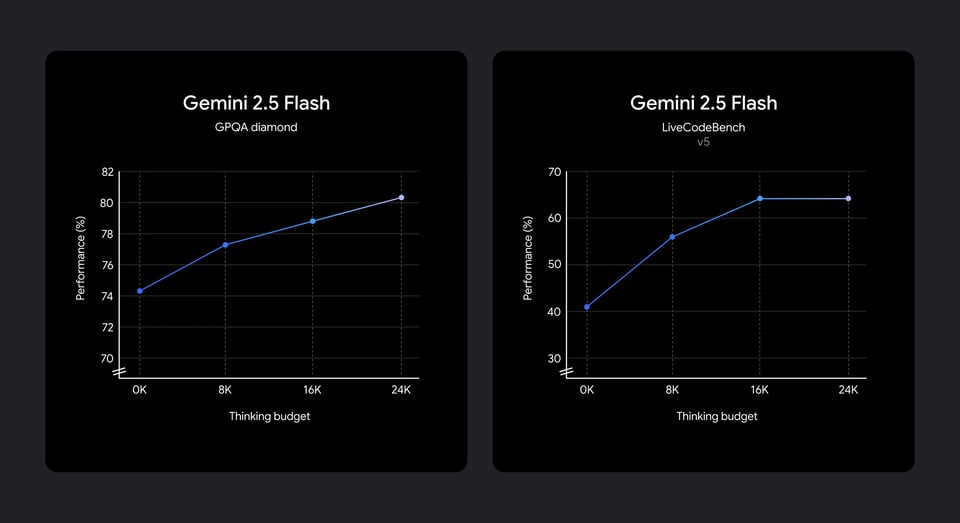
Performances de raisonnement de Gemini 2.5 Flash API selon les budgets de réflexion
Les résultats de l'évaluation montrent également comment l'API Gemini 2.5 Flash convertit un budget de réflexion (« thinking budget ») supplémentaire en une meilleure qualité de raisonnement. À mesure que ce budget augmente, les performances progressent régulièrement sur les benchmarks scientifiques et de codage, avec des gains particulièrement notables pour des budgets faibles à moyens avant de se stabiliser. Ce comportement indique que l'API Gemini 2.5 Flash traduit efficacement le calcul de raisonnement supplémentaire en améliorations tangibles, tout en montrant des rendements décroissants au-delà de certains seuils, favorisant ainsi un raisonnement contrôlé et respectueux du budget dans les applications réelles.
Déploiement et intégration de l'API Gemini 2.5 Flash sur Kie.ai
Lancez-vous avec notre produit en quelques étapes simples...
Étape 1 : S'inscrire sur Kie.ai et créer une clé d'API Gemini 2.5 Flash
Commencez par vous inscrire sur Kie.ai et créer votre clé d'API Gemini 2.5 Flash depuis le tableau de bord développeur. Cette clé est requise pour authentifier les requêtes et lier l'utilisation de l'API Gemini 2.5 Flash à votre compte, vos projets et vos environnements.
Étape 2 : Sélectionner l'API Gemini 2.5 Flash et configurer les paramètres de raisonnement
Une fois votre clé d'API disponible, sélectionnez l'API Gemini 2.5 Flash comme modèle cible. À cette étape, vous pouvez configurer la manière dont le raisonnement s'applique lors de l'utilisation de l'API, notamment en l'activant ou en le désactivant, et en définissant un budget de réflexion approprié pour contrôler la profondeur de raisonnement.
Étape 3 : Intégrer l'API Gemini 2.5 Flash dans le workflow de votre application
Intégrez l'API Gemini 2.5 Flash à votre service backend, workflow d'agent ou pipeline d'automatisation via votre clé API Gemini 2.5 Flash. L'API Gemini 2.5 Flash prend en charge les entrées textuelles et multimodales ainsi que les prompts structurés, permettant aux applications d'adopter l'API Gemini 2.5 Flash sans modification de l'architecture système existante.
Étape 4 : Déployez et optimisez l'API Gemini 2.5 Flash en production
Déployez votre application et observez les performances de l'API Gemini 2.5 Flash sous des charges de travail de production réelles. Affinez le comportement de raisonnement, les budgets de réflexion et la structure des prompts pour atteindre l'équilibre souhaité entre qualité de réponse et latence. Kie.ai offre une visibilité sur l'utilisation pour aider les équipes à scaler les déploiements de l'API Gemini 2.5 Flash tout en maintenant des performances prévisibles.
Comment l'API Gemini 2.5 Flash adapte son raisonnement à la complexité de la tâche
Mode à raisonnement léger : tâches directes et légères
Les prompts à raisonnement léger correspondent aux tâches dont l'intention est claire et dont la réponse ne nécessite pas d'analyse en plusieurs étapes ou de planification. Dans ce mode, l'API Gemini 2.5 Flash se concentre sur une génération rapide et directe, ce qui la rend adaptée aux traductions, aux requêtes factuelles simples et aux transformations de texte directes. Le modèle applique un raisonnement interne minimal, privilégiant une faible latence et une exécution efficace.
Mode à raisonnement intermédiaire : logique structurée et planification
Les requêtes nécessitant un raisonnement intermédiaire impliquent de multiples contraintes, des étapes logiques ou une planification légère. Pour ces tâches, l'API Gemini 2.5 Flash engage un niveau de raisonnement modéré pour évaluer les conditions, comparer les options et produire des résultats cohérents et structurés. Ce mode s'active généralement pour les problèmes de probabilités, les scénarios de planification et les tâches de décision à conditions multiples, où le raisonnement améliore la justesse sans nécessiter de calculs analytiques approfondis.
Mode Raisonnement Avancé : Analyse multi-étapes et résolution de problèmes
Les requêtes nécessitant un raisonnement poussé exigent un raisonnement interne soutenu sur de nombreuses étapes, impliquant souvent de la logique formelle, des mathématiques ou la résolution de dépendances complexes. Dans ce mode, l'API Gemini 2.5 Flash alloue une plus grande part de sa capacité de raisonnement pour décomposer le problème, suivre les états intermédiaires et vérifier la cohérence avant de produire un résultat. Ce niveau est typiquement utilisé pour les calculs d'ingénierie, la résolution de problèmes algorithmiques et les tâches liées au code, où la précision dépend d'un raisonnement structuré et approfondi.
Pourquoi choisir la plateforme Kie.ai pour l'API Gemini 2.5 Flash ?
Tarification abordable de l'API Gemini 2.5 Flash
Kie.ai propose un accès économique à l'API Gemini 2.5 Flash, rendant les capacités de raisonnement hybride abordables tant pour l'expérimentation que pour la production. La structure tarifaire est conçue pour gérer d'importants volumes de travail sans frais superflus, permettant aux équipes de passer à l'échelle leur utilisation de l'API Gemini 2.5 Flash en toute confiance.
Documentation complète de l'API Gemini 2.5 Flash
L'API Gemini 2.5 Flash sur Kie.ai bénéficie d'une documentation développeur claire et structurée. Elle couvre l'authentification, le comportement de raisonnement, les budgets de réflexion (thinking budgets), l'utilisation des contextes longs et les flux de déploiement. Ces ressources exhaustives permettent aux développeurs d'intégrer l'API Gemini 2.5 Flash efficacement, sans avoir recours à des références fragmentées ou externes.
Support 24h/24 et 7j/7 pour l'API Gemini 2.5 Flash
Kie.ai offre une assistance continue aux utilisateurs de l'API Gemini 2.5 Flash. Qu'il s'agisse de tester des intégrations, de déployer en production ou de résoudre des comportements inattendus, notre support 24h/24 et 7j/7 garantit que les applications alimentées par l'API Gemini 2.5 Flash restent fiables et opérationnelles à tout moment.