Automatically append previous messages to maintain multi-turn context. May increase token usage.
How can I help you today?
Complete guide to using
API Claude Opus 4.6 abordable sur Kie.ai
Accédez à l'API Anthropic Claude Opus 4.6 sur Kie.ai pour le codage, le raisonnement et les workflows à long contexte avec un déploiement plus économique.

Nouveautés de l'API Anthropic Claude Opus 4.6
Codage, débogage et revue de code renforcés avec l'API Claude Opus 4.6
L'API Claude Opus 4.6 offre une nette amélioration des performances en développement logiciel. Elle gère les tâches de codage avec une meilleure planification, accroît la précision du débogage et assure des revues de code plus fiables sur des bases de code plus vastes et complexes. Par rapport aux modèles Opus précédents, l'API Claude Opus 4.6 repère mieux les erreurs, revoit son raisonnement et maintient la qualité tout au long des workflows de développement en plusieurs étapes.
Fenêtre contextuelle de 1 million de tokens pour l'API Claude Opus 4.6
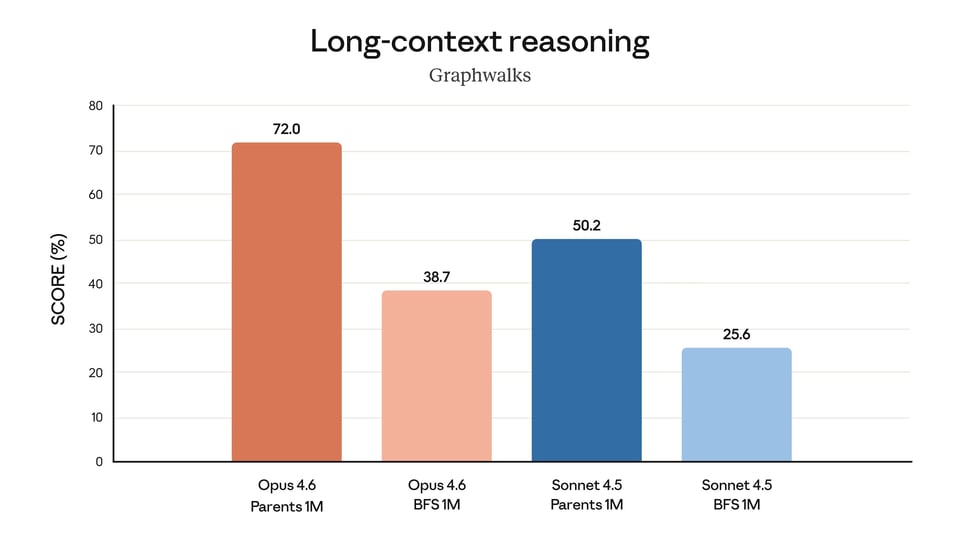
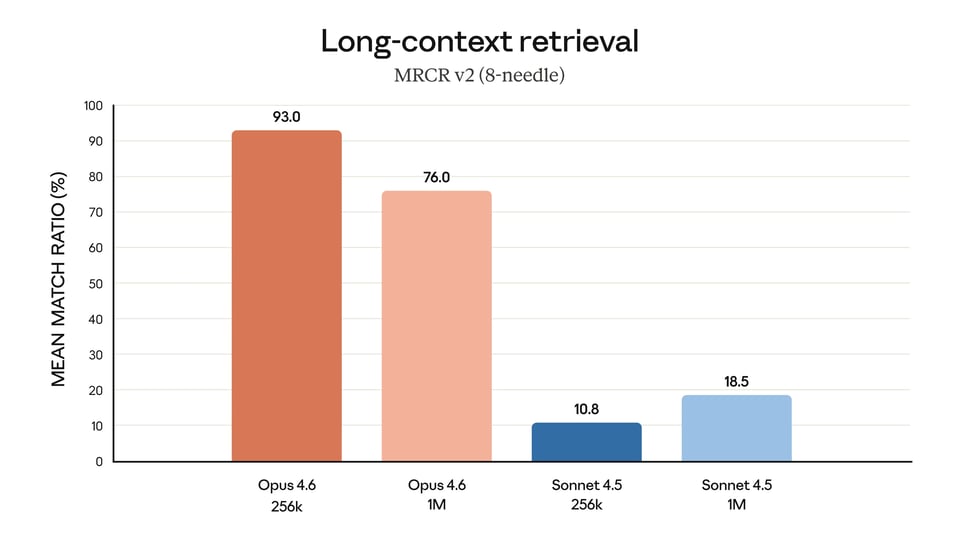
Grosse nouveauté pour l'API Claude Opus 4.6 : l'arrivée d'une fenêtre de contexte d'un million de tokens en version bêta. Cela confère à l'API Claude Opus 4.6 une assise bien plus solide pour le traitement de documents longs, la recherche dans de grands contextes et le raisonnement approfondi sur des entrées denses. Cette fonctionnalité est conçue pour réduire la dérive du contexte et améliorer les performances sur les tâches nécessitant le suivi d'informations à travers de très grands volumes de texte.
Raisonnement adaptatif, contrôles d'effort et compression du contexte dans l'API Claude Opus 4.6
L'API Claude Opus 4.6 intègre de nouvelles commandes rendant le modèle plus pratique pour une utilisation en production. Le raisonnement adaptatif permet à Claude Opus 4.6 d'approfondir sa réflexion lorsque nécessaire, tandis que les contrôles d'effort offrent aux développeurs plus de flexibilité pour équilibrer intelligence, latence et coût. La compression du contexte aide également Claude Opus 4.6 à gérer des conversations plus longues et des workflows d'agents en résumant l'historique du contexte avant que les limites ne soient atteintes.
128k tokens de sortie : L'API Claude Opus 4.6 voit plus grand pour les tâches complexes
L'API Claude Opus 4.6 prend désormais en charge jusqu'à 128k tokens en sortie, ce qui en fait l'outil idéal pour les tâches nécessitant de longues réponses en une seule exécution. C'est particulièrement utile pour la génération de contenus longs, les transformations de code volumineuses, la production de documents structurés et autres workflows qui nécessitaient auparavant d'être divisés en plusieurs requêtes. Avec cette capacité accrue, Claude Opus 4.6 devient plus pertinent pour les applications exigeant des résultats complets et détaillés.
Comment déployer l'API Claude Opus 4.6 à un tarif abordable sur Kie.ai
Lancez-vous avec notre produit en quelques étapes simples...
Inscrivez-vous sur Kie.ai et obtenez votre clé API Claude Opus 4.6
Commencez par créer votre compte Kie.ai pour accéder à l'API Claude Opus 4.6. Une fois inscrit, vous pourrez générer votre clé API depuis le tableau de bord et préparer votre environnement d'intégration. Vous disposerez ainsi d'un point de départ direct pour tester les requêtes, authentifier les appels et développer avec l'API Claude Opus 4.6 au sein d'un workflow optimisé pour les développeurs.
Testez gratuitement l'API Claude Opus 4.6 dans le Playground
Avant de passer au développement, utilisez le Playground pour essayer l'API Claude Opus 4.6 gratuitement. C'est le moyen le plus rapide d'évaluer la qualité des réponses, d'explorer le comportement des prompts et de comprendre les performances du modèle pour le codage, la gestion de longs contextes, le raisonnement ou les tâches basées sur des agents. Cela aide également les équipes à valider les cas d'usage en amont tout en découvrant la tarification abordable de l'API Claude Opus 4.6 sur Kie.ai.
Intégrez l'API Claude Opus 4.6 à votre application
Après vos tests dans le Playground, connectez l'API Claude Opus 4.6 à votre propre application ou workflow. Utilisez votre clé API pour envoyer des requêtes depuis votre backend, votre chaîne d'outils ou votre plateforme interne, puis commencez à intégrer le modèle à la logique réelle de votre produit. Cette étape transforme l'expérimentation initiale sur Kie.ai en une implémentation opérationnelle pour le chat, le codage, le traitement de documents ou les cas d'usage basés sur des agents.
Configurez l'API Claude Opus 4.6 pour la production
Une fois l'intégration de base opérationnelle, ajustez votre implémentation aux exigences de la production. Définissez la structure de requête adéquate, affinez vos prompts pour une meilleure stabilité et optimisez l'utilisation selon la complexité, la latence et les coûts. Cela rend l'API Claude Opus 4.6 plus adaptée à un déploiement à long terme, plutôt qu'à de simples tests ponctuels.
Déployez l'API Claude Opus 4.6 à grande échelle avec Kie.ai
Une fois votre workflow validé, passez au déploiement complet de l'API Claude Opus 4.6. C'est à ce stade que les équipes étendent généralement son utilisation aux produits destinés aux clients, à l'automatisation interne, aux flux de recherche ou aux outils de développement. Avec Kie.ai, le parcours du test à l'intégration puis au déploiement est plus direct, ce qui permet de mieux apprécier les tarifs avantageux de Claude Opus 4.6 en conditions réelles.
Claude Opus 4.6 vs Gemini 3.1 Pro, GPT-5.4 et autres modèles Claude
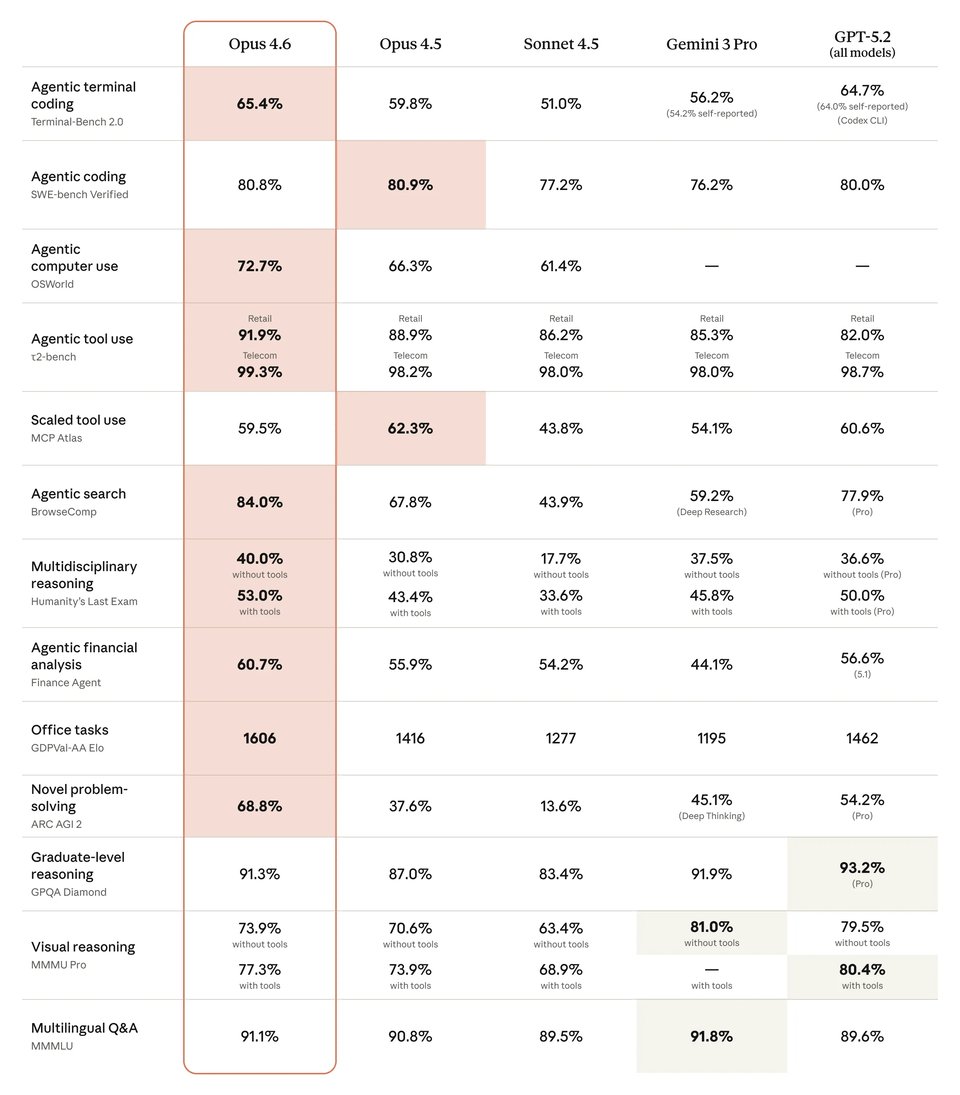
Claude Opus 4.6 affiche de solides performances dans les benchmarks de codage, d'utilisation de l'ordinateur, de recherche et de raisonnement avancé face à Gemini 3.1 Pro, GPT-5.4 et aux modèles Claude précédents. Dans le comparatif ci-dessous, Claude Opus 4.6 devance nettement Claude Opus 4.5, Claude Sonnet 4.5 et Gemini 3.1 Pro sur plusieurs flux de travail critiques à haute valeur ajoutée, tandis que GPT-5.4 reste très compétitif dans des domaines tels que le codage sur terminal, l'utilisation de l'ordinateur et le raisonnement de niveau universitaire. Cela fait de Claude Opus 4.6 un choix incontournable pour les équipes évaluant la performance des modèles, tant pour les tâches d'agents autonomes que pour le travail cognitif axé sur la production.
| Benchmark | Claude Opus 4.6 | Claude Opus 4.5 | Claude Sonnet 4.5 | Gemini 3.1 Pro | GPT-5.4 |
|---|---|---|---|---|---|
| Agentic terminal coding | 65.40% | 59.80% | 51.00% | 68.50% | 75.10% |
| Agentic computer use | 72.70% | 66.30% | 61.40% | — | 75.00% |
| Agentic search | 84.00% | 67.80% | 43.90% | 85.90% | 82.70% |
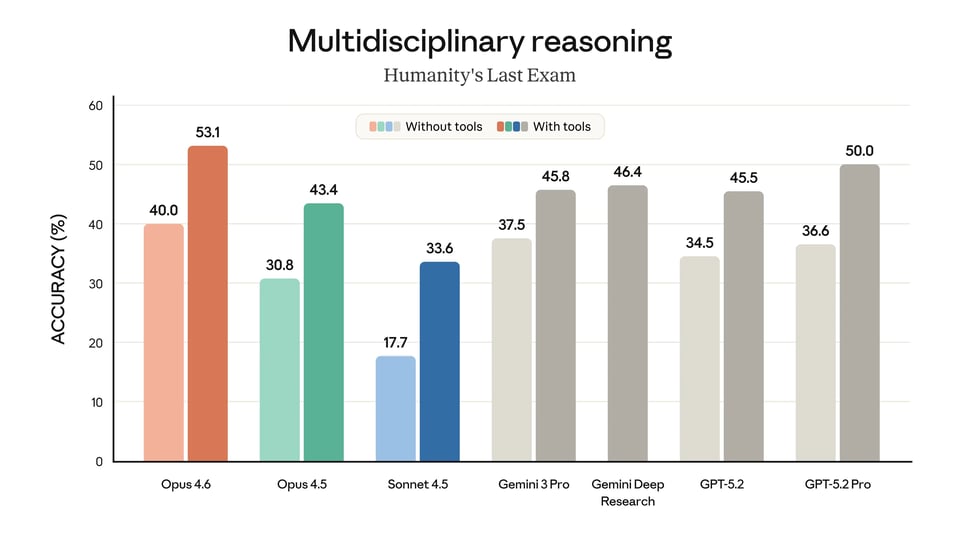
| Multidisciplinary reasoning (no tools) | 40.00% | 30.80% | 17.70% | 44.70% | 39.80% |
| Multidisciplinary reasoning (with tools) | 53.00% | 43.40% | 33.60% | — | 52.10% |
| Graduate-level reasoning | 91.30% | 87.00% | 83.40% | 94.30% | 92.80% |