Automatically append previous messages to maintain multi-turn context. May increase token usage.
How can I help you today?
API asequible de Gemini 2.5 Flash para razonamiento híbrido e inferencia rápida
Despliega la API de Gemini 2.5 Flash en Kie.ai para obtener un razonamiento híbrido rentable, pensamiento controlable y un rendimiento escalable para producción.
Presentamos el primer LLM de razonamiento híbrido de Google: Gemini 2.5 Flash
Gemini 2.5 Flash es el primer modelo de lenguaje grande (LLM) de razonamiento totalmente híbrido de Google, diseñado para combinar la generación rápida de respuestas con un razonamiento interno opcional en un solo modelo. A diferencia de los modelos Flash anteriores que priorizan la respuesta inmediata, Gemini 2.5 Flash puede activar una fase de razonamiento solo cuando la tarea lo requiere, lo que permite al mismo modelo manejar tanto solicitudes de baja latencia como cargas de trabajo complejas de razonamiento de varios pasos. Este comportamiento híbrido está disponible a través de la API de Gemini 2.5 Flash, donde los desarrolladores pueden controlar cuándo aplicar el razonamiento y gestionar el equilibrio entre calidad, latencia y costos en entornos de producción.
Características principales de la API Gemini 2.5 Flash de Google DeepMind
El primer LLM de razonamiento híbrido de Google en la API de Gemini 2.5 Flash
La API de Gemini 2.5 Flash ofrece acceso al primer modelo de lenguaje grande (LLM) de razonamiento totalmente híbrido de Google. Creado para combinar una generación rápida de respuestas con un razonamiento interno opcional en un único LLM, este diseño híbrido aplica el razonamiento solo cuando la tarea lo requiere. Esto permite que la API de Gemini 2.5 Flash maneje tanto solicitudes de baja latencia como cargas de trabajo complejas de razonamiento de varios pasos, sin necesidad de cambiar de modelo ni de flujos de trabajo.
Arquitectura de contexto de un millón de tokens con la API de Gemini 2.5 Flash
La API de Gemini 2.5 Flash se basa en una arquitectura de un millón de tokens de contexto y admite hasta 1.048.576 tokens de entrada en una sola solicitud. Esto permite al modelo razonar sobre documentos completos, grandes bases de código, largas conversaciones y conjuntos de datos multimodales como un contexto unificado, sin depender de una fragmentación agresiva ni de sistemas de memoria externos. Al mantener la información de largo alcance totalmente en contexto, la API de Gemini 2.5 Flash ofrece un razonamiento más consistente, referencias cruzadas más precisas y resultados más fiables para flujos de trabajo de contexto extenso.
Entradas multimodales y salidas estructuradas en la API de Gemini 2.5 Flash
La API de Gemini 2.5 Flash acepta entradas de texto, imagen, vídeo y audio, y genera salidas de texto estructuradas. Gracias al soporte nativo para salidas estructuradas, los desarrolladores pueden diseñar flujos de trabajo que analicen un contexto multimodal enriquecido y devuelvan respuestas predecibles y legibles por máquina. Esto hace que la API de Gemini 2.5 Flash sea ideal para aplicaciones que requieren formatos de salida estrictos junto con una comprensión multimodal compleja.
Capacidades de razonamiento y herramientas integradas en la API de Gemini 2.5 Flash
La API de Gemini 2.5 Flash incluye soporte nativo para razonamiento híbrido (thinking), llamadas a funciones, ejecución de código, búsqueda de archivos, contexto de URL, fundamentación en búsquedas (grounding), procesamiento por lotes y caché. Estas capacidades integradas permiten a las aplicaciones combinar el razonamiento con herramientas externas y fuentes de datos en una sola solicitud, lo que facilita despliegues escalables y con costes controlados en entornos de producción.
Resultados de los benchmarks y rendimiento del modelo Gemini 2.5 Flash
Rendimiento de la API Gemini 2.5 Flash en la familia de modelos Gemini
En las evaluaciones internas, el modelo Gemini 2.5 Flash ocupa una posición claramente definida dentro de la familia Gemini. Ofrece un aumento sustancial de capacidad respecto a variantes anteriores, como Gemini 2.0 Flash y Flash Lite, manteniéndose intencionalmente por debajo de Gemini 2.5 Pro. Esto refleja el rol de la API Gemini 2.5 Flash como un modelo de razonamiento híbrido diseñado para servir de puente entre los modelos Flash de baja latencia y los de razonamiento de alta capacidad, representando un avance significativo en la familia Flash más que una simple actualización menor.
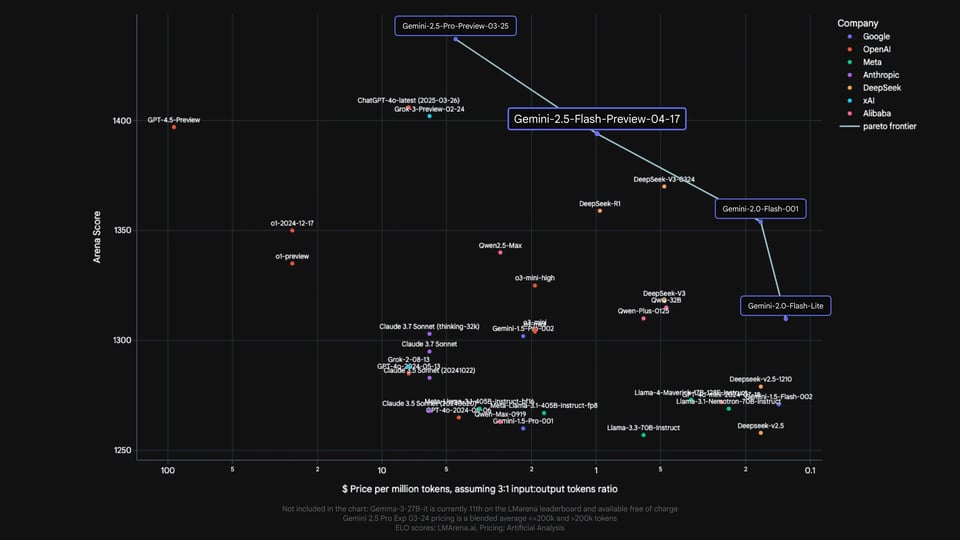
Comparativa de la API Gemini 2.5 Flash frente a modelos de razonamiento de vanguardia
Los resultados de los benchmarks oficiales publicados por Google evalúan el modelo Gemini 2.5 Flash junto a modelos de razonamiento de vanguardia de OpenAI, Anthropic, xAI y DeepSeek, incluyendo o4-mini, Claude Sonnet 3.7, Grok 3 y DeepSeek R1. En áreas como matemáticas, ciencias, programación, comprensión multimodal y contexto largo, la API Gemini 2.5 Flash demuestra un rendimiento competitivo, destacando especialmente en tareas de razonamiento complejo y evaluaciones de contexto extenso. Estas comparativas se ofrecen solo como referencia de capacidades. Cualquier información de precios mostrada en los materiales originales pertenece a la publicación de Google y no representa los precios en Kie.ai.
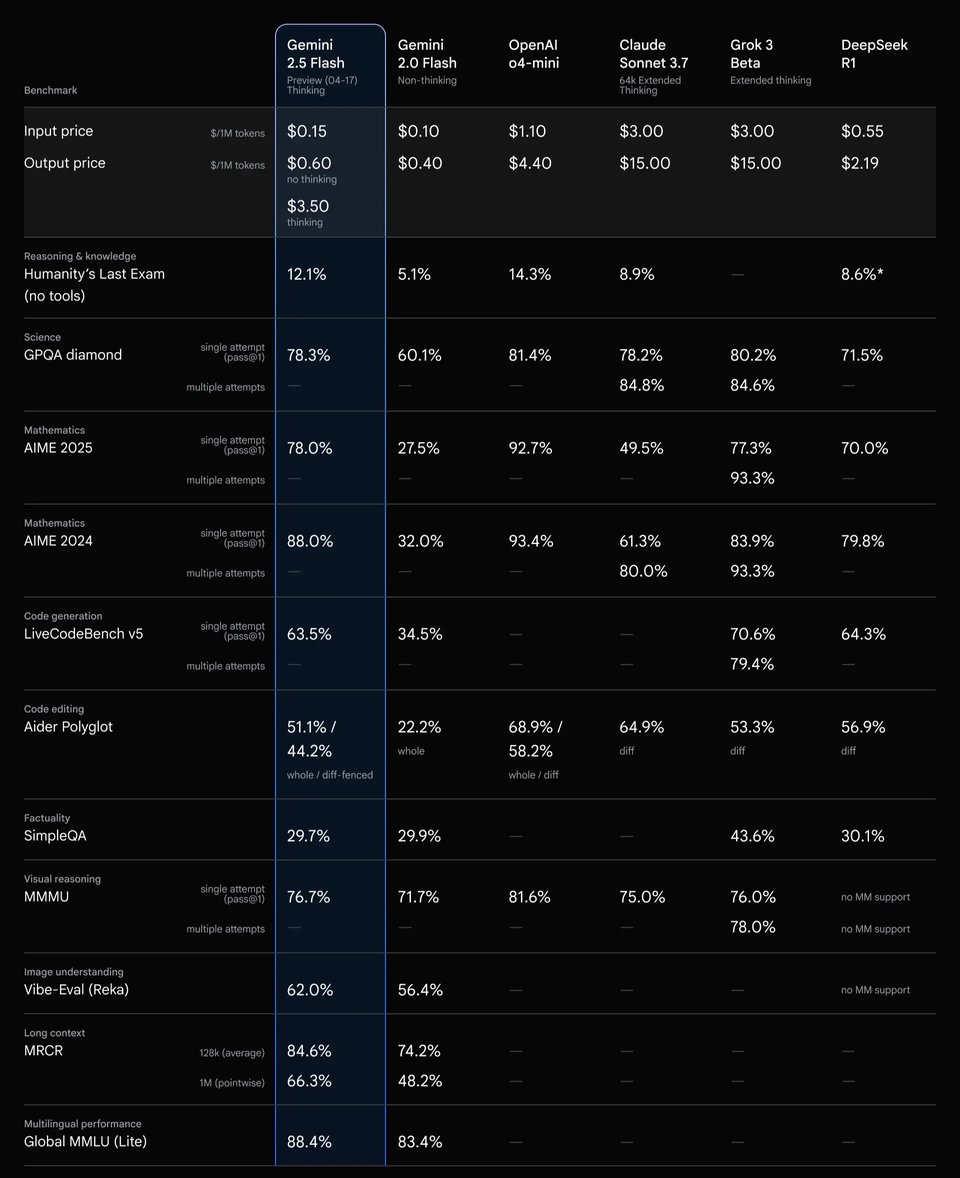
Rendimiento de razonamiento de la API Gemini 2.5 Flash con distintos niveles de razonamiento
Las evaluaciones demuestran cómo la API de Gemini 2.5 Flash transforma un mayor presupuesto de pensamiento en una calidad de razonamiento superior. Al asignar más recursos, el rendimiento mejora constantemente en pruebas científicas y de programación, logrando los mayores avances en rangos bajos y medios antes de estabilizarse. Esto indica que la API de Gemini 2.5 Flash traduce eficazmente el cómputo adicional en mejoras medibles, con rendimientos decrecientes tras ciertos umbrales, lo que facilita un razonamiento controlado y eficiente en aplicaciones reales.
Despliegue e integración de la API de Gemini 2.5 Flash en Kie.ai
Empieza a usar nuestro producto en unos sencillos pasos...
Paso 1: Regístrate en Kie.ai y crea una clave API para Gemini 2.5 Flash
Comienza registrándote en Kie.ai y generando tu clave API de Gemini 2.5 Flash desde el panel de desarrolladores. Esta clave es necesaria para autenticar las solicitudes y vincular el uso de la API de Gemini 2.5 Flash a tu cuenta, proyectos y entornos.
Paso 2: Selecciona la API de Gemini 2.5 Flash y configura los ajustes de razonamiento
Una vez que dispongas de tu clave API, selecciona la API de Gemini 2.5 Flash como modelo de destino. En este paso, puedes configurar cómo se aplica el razonamiento al usar la API de Gemini 2.5 Flash, incluyendo la opción de activarlo o desactivarlo y establecer un presupuesto de pensamiento adecuado para controlar la profundidad del razonamiento.
Paso 3: Integra la API de Gemini 2.5 Flash en el flujo de trabajo de tu aplicación
Integra la API de Gemini 2.5 Flash en tu servicio backend, flujo de trabajo de agentes o pipeline de automatización utilizando tu clave de API de Gemini 2.5 Flash. La API de Gemini 2.5 Flash admite entradas de texto y multimodales, así como prompts estructurados, lo que permite a las aplicaciones adoptar la API de Gemini 2.5 Flash sin modificar la arquitectura del sistema existente.
Paso 4: Despliega y optimiza la API de Gemini 2.5 Flash en producción
Despliega tu aplicación y observa el rendimiento de la API de Gemini 2.5 Flash con cargas de trabajo reales en producción. Ajusta el comportamiento de razonamiento, los presupuestos de pensamiento y la estructura de los prompts para lograr el equilibrio ideal entre calidad de respuesta y latencia. Kie.ai proporciona visibilidad del uso para ayudar a los equipos a escalar las implementaciones de la API de Gemini 2.5 Flash manteniendo un rendimiento predecible.
Cómo la API de Gemini 2.5 Flash adapta el razonamiento a la complejidad de la tarea
Modo de bajo razonamiento: tareas directas y ligeras
Los prompts de bajo razonamiento son tareas donde la intención es clara y la respuesta no requiere análisis ni planificación en varios pasos. En este modo, la API de Gemini 2.5 Flash se centra en una generación rápida y directa, lo que la hace ideal para traducciones, consultas factuales simples y transformaciones de texto sencillas. El modelo aplica un razonamiento interno mínimo, priorizando la baja latencia y una ejecución eficiente.
Modo de razonamiento medio: lógica estructurada y planificación
Los prompts de razonamiento medio implican múltiples restricciones, pasos lógicos o una planificación básica. Para estas tareas, la API de Gemini 2.5 Flash activa un nivel moderado de razonamiento interno para evaluar condiciones, comparar opciones y generar respuestas coherentes y estructuradas. Este modo suele activarse con problemas de probabilidad, gestión de agendas y tareas de toma de decisiones con múltiples condiciones, donde el razonamiento mejora la precisión sin requerir un cálculo analítico profundo.
Modo de razonamiento avanzado: Análisis de varios pasos y resolución de problemas
Los prompts de razonamiento avanzado requieren un razonamiento interno sostenido a través de muchos pasos, involucrando a menudo lógica formal, matemáticas o la resolución de dependencias complejas. En este modo, la API de Gemini 2.5 Flash asigna una mayor parte de su capacidad de razonamiento para desglosar el problema, rastrear estados intermedios y verificar la coherencia antes de generar un resultado. Este nivel se utiliza habitualmente para cálculos de ingeniería, resolución de problemas algorítmicos y tareas relacionadas con el código, donde la precisión depende de un razonamiento profundo y estructurado.
¿Por qué elegir Kie.ai como tu plataforma para la API Gemini 2.5 Flash?
Precios asequibles para la API de Gemini 2.5 Flash
Kie.ai ofrece un acceso económico a la API de Gemini 2.5 Flash, haciendo que las capacidades de razonamiento híbrido sean asequibles tanto para la experimentación como para el uso en producción. La estructura de precios está diseñada para soportar grandes volúmenes de trabajo sin generar costes innecesarios, permitiendo a los equipos escalar el uso de la API de Gemini 2.5 Flash con total confianza.
Documentación completa de la API Gemini 2.5 Flash
La API Gemini 2.5 Flash en Kie.ai cuenta con una documentación para desarrolladores clara y estructurada, que abarca desde la autenticación y el comportamiento de razonamiento hasta los presupuestos de pensamiento, el uso de contextos largos y los flujos de trabajo de despliegue. Esta documentación integral ayuda a los desarrolladores a integrar la API Gemini 2.5 Flash de manera eficiente, sin depender de referencias externas o fragmentadas.
Soporte 24/7 para la API Gemini 2.5 Flash
Kie.ai ofrece asistencia ininterrumpida a los usuarios de la API Gemini 2.5 Flash. Tanto si estás realizando pruebas de integración como desplegando en producción o resolviendo problemas inesperados, nuestro soporte 24/7 garantiza que las aplicaciones impulsadas por la API Gemini 2.5 Flash permanezcan fiables y operativas en todo momento.