Automatically append previous messages to maintain multi-turn context. May increase token usage.
How can I help you today?
Kostengünstige Gemini 2.5 Flash API für Hybrid-Reasoning und schnelle Inferenz
Stellen Sie die Gemini 2.5 Flash API auf Kie.ai bereit für kosteneffizientes Hybrid-Reasoning, steuerbare Denkprozesse und skalierbare Performance.
Wir stellen vor: Googles erstes Hybrid-Reasoning-LLM – Gemini 2.5 Flash
Gemini 2.5 Flash ist Googles erstes Large Language Model (LLM) mit vollständig hybridem Reasoning, entwickelt, um schnelle Antwortgenerierung mit optionalem internen Reasoning in einem einzigen Modell zu kombinieren. Im Gegensatz zu früheren Flash-Modellen, die auf sofortige Ausgabe priorisiert waren, aktiviert Gemini 2.5 Flash eine Reasoning-Phase nur dann, wenn die Aufgabe dies erfordert. Dadurch kann dasselbe Modell sowohl Anfragen mit niedriger Latenz als auch komplexe Workloads mit mehrstufigem Reasoning unterstützen. Dieses hybride Verhalten wird über die Gemini 2.5 Flash API bereitgestellt, sodass Entwickler steuern können, wann Reasoning eingesetzt wird, um in Produktionsumgebungen das Verhältnis zwischen Ausgabequalität, Latenz und Kosten optimal zu managen.
Hauptmerkmale der Google DeepMind Gemini 2.5 Flash API
Googles erstes LLM mit hybridem Reasoning in der Gemini 2.5 Flash API
Die Gemini 2.5 Flash API stellt Googles erstes LLM mit vollständig hybridem Reasoning bereit. Das Modell kombiniert schnelle Antwortgenerierung mit optionalem internen Reasoning in einer einzigen Lösung. Dank dieses hybriden Designs wird Reasoning nur bei Bedarf angewendet, sodass Gemini 2.5 Flash sowohl Anfragen mit niedriger Latenz als auch komplexe Workloads mit mehrstufigem Reasoning unterstützt – ganz ohne Modell- oder Pipeline-Wechsel.
Architektur mit einem 1-Millionen-Token-Kontextfenster in der Gemini 2.5 Flash API
Die Gemini 2.5 Flash API basiert auf einer Architektur mit einem Kontextfenster von einer Million Token und unterstützt bis zu 1.048.576 Eingabe-Token in einer einzigen Anfrage. Dies ermöglicht es dem Modell, ganze Dokumente, umfangreiche Codebasen, lange Konversationen und multimodale Datensätze als einen einheitlichen Kontext zu verarbeiten, ohne auf aggressives Chunking oder externe Speichersysteme angewiesen zu sein. Da Informationen über den gesamten Kontext hinweg erhalten bleiben, liefert die Gemini 2.5 Flash API konsistenteres Reasoning, präzisere Querverweise und zuverlässigere Ergebnisse für Long-Context-Workflows.
Multimodale Eingaben und strukturierte Ausgaben in der Gemini 2.5 Flash API
Die Gemini 2.5 Flash API verarbeitet Text-, Bild-, Video- und Audio-Eingaben und generiert strukturierte, textbasierte Ausgaben. Dank der integrierten Unterstützung für strukturierte Ausgaben können Entwickler Workflows erstellen, die komplexe multimodale Kontexte analysieren und vorhersehbare, maschinenlesbare Antworten liefern. Damit eignet sich die Gemini 2.5 Flash API ideal für Anwendungen, die ein komplexes multimodales Verständnis mit strikten Ausgabeformaten kombinieren müssen.
Integrierte Reasoning- und Tooling-Funktionen in der Gemini 2.5 Flash API
Die Gemini 2.5 Flash API bietet native Unterstützung für hybrides Reasoning (Thinking), Function Calling, Code Execution, Dateisuche, URL-Kontext, Search Grounding, Batch-Verarbeitung und Caching. Diese integrierten Funktionen ermöglichen es Anwendungen, Reasoning mit externen Tools und Datenquellen in einer einzigen Anfrage zu kombinieren. Das sorgt für skalierbare und kosteneffiziente Deployments in Produktionsumgebungen.
Benchmark-Ergebnisse und Modellleistung der Gemini 2.5 Flash API
Leistung von Gemini 2.5 Flash innerhalb der Gemini-Modellfamilie
In internen Auswertungen nimmt Gemini 2.5 Flash eine klar definierte Position innerhalb der Gemini-Modellfamilie ein. Es bietet eine erhebliche Leistungssteigerung gegenüber früheren Varianten wie Gemini 2.0 Flash und Flash Lite, ordnet sich aber bewusst unter Gemini 2.5 Pro ein. Dies unterstreicht die Rolle der Gemini 2.5 Flash API als hybrides Reasoning-Modell: Sie schlägt die Brücke zwischen latenzarmen Flash-Modellen und leistungsstarken Reasoning-Modellen und stellt einen bedeutenden Fortschritt innerhalb der Flash-Familie dar – weit mehr als nur ein kleines, inkrementelles Update.
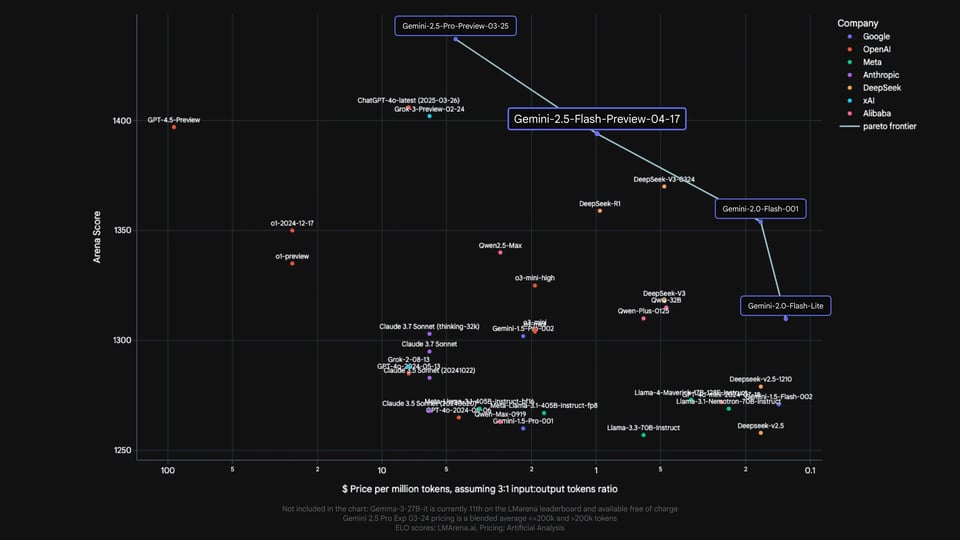
Benchmarks der Gemini 2.5 Flash API im Vergleich zu führenden Reasoning-Modellen
Die von Google veröffentlichten offiziellen Benchmark-Ergebnisse vergleichen Gemini 2.5 Flash mit weit verbreiteten, führenden Reasoning-Modellen von OpenAI, Anthropic, xAI und DeepSeek, darunter Modelle wie o4-mini, Claude Sonnet 3.7, Grok 3 und DeepSeek R1. In den Bereichen Mathematik, Wissenschaft, Coding, multimodales Verständnis und Long-Context-Benchmarks zeigt die Gemini 2.5 Flash API eine wettbewerbsfähige Performance, insbesondere bei Aufgaben, die komplexes Reasoning und lange Kontexte erfordern. Diese Vergleiche dienen lediglich als Referenz für die Leistungsfähigkeit. Alle Preisangaben in den Original-Benchmarks stammen von Google und gelten nicht für Kie.ai.
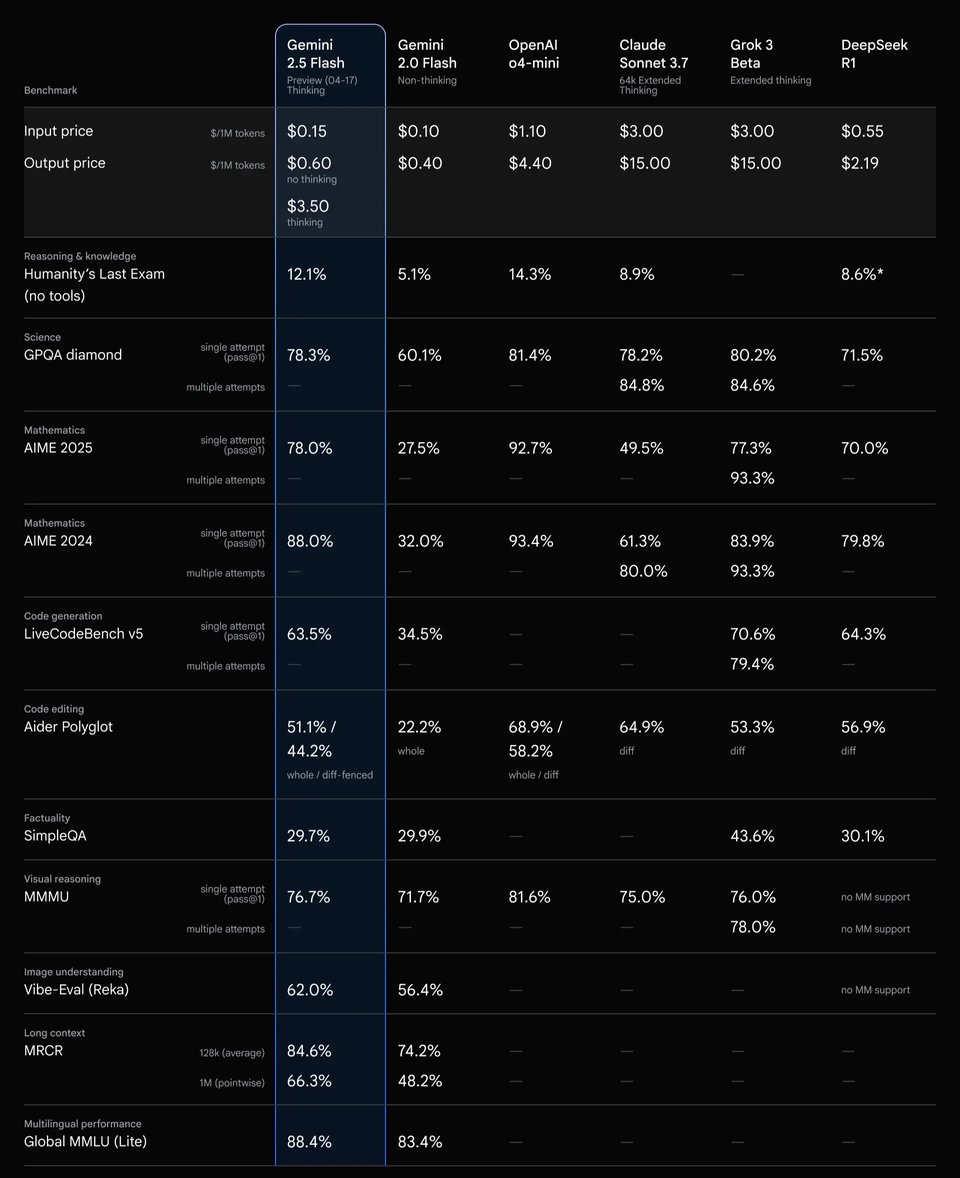
Reasoning-Performance der Gemini 2.5 Flash API bei verschiedenen Thinking Budgets
Die Evaluierungsergebnisse verdeutlichen, wie die Gemini 2.5 Flash API zusätzliches Thinking Budget in eine höhere Reasoning-Qualität umwandelt. Mit steigendem Reasoning-Budget nimmt die Leistung bei Benchmarks für wissenschaftliches Reasoning und Coding stetig zu. Die signifikantesten Zuwächse zeigen sich im niedrigen bis mittleren Budgetbereich, bevor die Kurve allmählich abflacht. Dies belegt, dass die Gemini 2.5 Flash API zusätzliche Rechenleistung effektiv in messbare Qualitätssteigerungen übersetzt. Gleichzeitig zeigt sich ab gewissen Schwellenwerten ein abnehmender Grenznutzen – ein Verhalten, das gesteuertes, budgetbewusstes Reasoning in realen Anwendungen unterstützt.
Deployment und Integration der Gemini 2.5 Flash API auf Kie.ai
Starten Sie mit unserem Produkt in nur wenigen einfachen Schritten...
Schritt 1: Auf Kie.ai registrieren und Gemini 2.5 Flash API-Key erstellen
Registrieren Sie sich zunächst auf Kie.ai und erstellen Sie Ihren Gemini 2.5 Flash API-Key im Entwickler-Dashboard. Der API-Key ist erforderlich, um Anfragen zu authentifizieren und die Nutzung der Gemini 2.5 Flash API mit Ihrem Konto, Ihren Projekten und Umgebungen zu verknüpfen.
Schritt 2: Gemini 2.5 Flash API auswählen und Reasoning-Einstellungen konfigurieren
Sobald Ihr API-Key bereitsteht, wählen Sie die Gemini 2.5 Flash API als Zielmodell aus. In diesem Schritt legen Sie fest, wie Reasoning bei der Nutzung der Gemini 2.5 Flash API angewendet wird. Hierbei können Sie das Reasoning aktivieren oder deaktivieren sowie ein passendes Budget festlegen, um die Reasoning-Tiefe zu steuern.
Schritt 3: Gemini 2.5 Flash API in Ihren Workflow integrieren
Integrieren Sie die Gemini 2.5 Flash API über Ihren API-Key in Ihren Backend-Dienst, Ihren Agenten-Workflow oder Ihre Automatisierungs-Pipeline. Da die Gemini 2.5 Flash API sowohl Text- als auch multimodale Eingaben sowie strukturierte Prompts unterstützt, können Anwendungen die Gemini 2.5 Flash API ohne Änderungen an der bestehenden Systemarchitektur einsetzen.
Schritt 4: Deployment und Optimierung der Gemini 2.5 Flash API im Produktivbetrieb
Deployen Sie Ihre Anwendung und beobachten Sie, wie die Gemini 2.5 Flash API unter realen Produktionslasten performt. Feinjustieren Sie das Reasoning-Verhalten, die Thinking-Budgets und die Prompt-Struktur, um die optimale Balance zwischen Antwortqualität und Latenz zu erreichen. Kie.ai bietet volle Transparenz über die Nutzung, damit Teams ihre Gemini 2.5 Flash API-Deployments skalieren können, während die Leistung vorhersagbar bleibt.
Wie die Gemini 2.5 Flash API das Reasoning an die Aufgabenkomplexität anpasst
Low-Reasoning-Modus: Direkte und leichtgewichtige Aufgaben
Low-Reasoning-Prompts sind Aufgaben mit klarer Absicht, bei denen die Antwort keine mehrstufige Analyse oder Planung erfordert. In diesem Modus konzentriert sich die Gemini 2.5 Flash API auf eine schnelle, direkte Generierung – ideal für Übersetzungen, einfache Faktenabfragen und direkte Textumwandlungen. Das Modell wendet minimales internes Reasoning an und priorisiert niedrige Latenz sowie effiziente Ausführung.
Medium-Reasoning-Modus: Strukturierte Logik und Planung
Prompts mit mittlerem Reasoning-Anspruch beinhalten mehrere Bedingungen, logische Schritte oder leichte Planungsaufgaben. Für diese Aufgaben nutzt die Gemini 2.5 Flash API ein moderates Maß an internem Reasoning, um Bedingungen zu bewerten, Optionen zu vergleichen und strukturierte Ergebnisse zu liefern. Dieser Modus greift häufig bei Wahrscheinlichkeitsrechnungen, Scheduling-Szenarien und Entscheidungsaufgaben mit mehreren Bedingungen, bei denen Reasoning die Korrektheit verbessert, ohne tiefgreifende analytische Berechnungen zu erfordern.
High-Reasoning-Modus: Mehrstufige Analyse und Problemlösung
High-Reasoning-Prompts erfordern anhaltendes internes Reasoning über viele Schritte hinweg, oft unter Einbeziehung formaler Logik, Mathematik oder komplexer Abhängigkeiten. In diesem Modus stellt die Gemini 2.5 Flash API einen größeren Teil ihrer Reasoning-Kapazität bereit, um das Problem zu zerlegen, Zwischenschritte zu verfolgen und die Konsistenz zu prüfen. Dieses Niveau wird typischerweise für technische Berechnungen, algorithmische Problemlösungen und Code-bezogene Aufgaben genutzt, bei denen Genauigkeit auf tiefgehendem, strukturiertem Reasoning basiert.
Warum Sie Kie.ai als Plattform für die Gemini 2.5 Flash API wählen sollten
Erschwingliche Preise für die Gemini 2.5 Flash API
Kie.ai bietet kosteneffizienten Zugriff auf die Gemini 2.5 Flash API und macht hybride Reasoning-Funktionen sowohl für Experimente als auch für den produktiven Einsatz erschwinglich. Die Preisstruktur ist für Workloads mit hohem Volumen ausgelegt, ohne unnötige Kosten zu verursachen, sodass Teams die Nutzung der Gemini 2.5 Flash API zuversichtlich skalieren können.
Umfassende Dokumentation zur Gemini 2.5 Flash API
Die Gemini 2.5 Flash API auf Kie.ai wird durch eine klare, strukturierte Entwicklerdokumentation unterstützt. Sie deckt Authentifizierung, Reasoning-Verhalten, Thinking-Budgets, die Nutzung langer Kontexte sowie Deployment-Workflows ab. Diese umfassenden Ressourcen ermöglichen Entwicklern eine effiziente Integration der Gemini 2.5 Flash API, ohne auf fragmentierte oder externe Referenzen angewiesen zu sein.
24/7-Support für die Gemini 2.5 Flash API
Kie.ai bietet rund um die Uhr Support für Nutzer der Gemini 2.5 Flash API. Ob bei Integrationstests, dem Deployment in die Produktion oder der Diagnose von unerwartetem Verhalten – unser 24/7-Service stellt sicher, dass Ihre auf der Gemini 2.5 Flash API basierenden Anwendungen jederzeit zuverlässig und betriebsbereit bleiben.