Automatically append previous messages to maintain multi-turn context. May increase token usage.
How can I help you today?
Complete guide to using
Kosteneffiziente Claude Opus 4.6 API auf Kie.ai
Zugriff auf die Anthropic Claude Opus 4.6 API über Kie.ai: Optimiert für Coding, Reasoning und Long-Context Workflows bei kosteneffizienterem Deployment.

Was ist neu bei der Anthropic Claude Opus 4.6 API
Leistungsfähigeres Coding, Debugging und Code-Review mit der Claude Opus 4.6 API
Die Claude Opus 4.6 API bietet ein deutliches Upgrade in der Software-Engineering-Performance. Sie bewältigt Coding-Aufgaben mit besserer Planung, erhöht die Debugging-Genauigkeit und führt Code-Reviews bei größeren und komplexeren Codebasen zuverlässiger durch. Im Vergleich zu früheren Opus-Modellen erkennt Claude Opus 4.6 Fehler besser, hinterfragt seine Schlussfolgerungen und hält die Qualität auch in mehrstufigen Entwicklungsprozessen hoch.
1-Million-Token-Kontextfenster für die Claude Opus 4.6 API
Eines der wichtigsten Updates in der Claude Opus 4.6 API ist die Einführung eines Kontextfensters von 1 Million Token (Beta). Dies verschafft der Claude Opus 4.6 API eine deutlich stärkere Basis für die Verarbeitung langer Dokumente, umfangreiche Kontextabrufe und erweitertes Reasoning bei komplexen Eingaben. Das Update minimiert Context Drift und verbessert die Leistung bei Aufgaben, die das Nachverfolgen von Informationen über sehr große Textmengen erfordern.
Adaptive Thinking, Effort Controls und Context Compaction in der Claude Opus 4.6 API
Die Claude Opus 4.6 API bietet neue Steuerungsoptionen, die das Modell für den Produktionseinsatz noch praktischer machen. Adaptive Thinking ermöglicht es der API, bei Bedarf tiefergehendes Reasoning anzuwenden, während Effort Controls Entwicklern mehr Flexibilität bieten, um Intelligenz, Latenz und Kosten optimal abzuwägen. Context Compaction unterstützt zudem längere Konversationen und agentenbasierte Workflows, indem ältere Kontexte zusammengefasst werden, bevor Limits erreicht sind.
128k Ausgabe-Token erweitern die Claude Opus 4.6 API für umfangreichere Aufgaben
Die Claude Opus 4.6 API unterstützt Ausgaben von bis zu 128k Token und eignet sich damit besser für Aufgaben, die umfangreiche Antworten in einem einzigen Request erfordern. Dies ist besonders nützlich für die Generierung langer Texte, große Code-Transformationen, strukturierte Dokumentenausgaben und andere Workflows, die sonst auf mehrere Requests aufgeteilt werden müssten. Mit der höheren Ausgabekapazität wird die Claude Opus 4.6 API deutlich effizienter für Anwendungen, die längere und vollständigere Ergebnisse benötigen.
So deployen Sie die Claude Opus 4.6 API kostengünstig mit Kie.ai
Legen Sie mit unserem Produkt in wenigen einfachen Schritten los...
Auf Kie.ai registrieren und Claude Opus 4.6 API-Key erhalten
Erstellen Sie zunächst Ihr Kie.ai-Konto, um Zugriff auf die Claude Opus 4.6 API zu erhalten. Nach der Registrierung können Sie Ihren API-Key direkt im Dashboard generieren und Ihre Umgebung für die Integration vorbereiten. Dies ist Ihr Startpunkt, um Anfragen zu testen, API-Aufrufe zu authentifizieren und mit der Entwicklung auf Basis der Claude Opus 4.6 API in einem entwicklerfreundlichen Workflow zu beginnen.
Claude Opus 4.6 API kostenlos im Playground testen
Nutzen Sie vor der Entwicklung den Playground, um die Claude Opus 4.6 API kostenlos auszuprobieren. Dies ist der schnellste Weg, die Antwortqualität zu prüfen, das Prompt-Verhalten zu erkunden und die Leistung des Modells bei Aufgaben in den Bereichen Coding, Long-Context, Reasoning oder Agenten zu verstehen. Teams können so Anwendungsfälle frühzeitig validieren und gleichzeitig die erschwinglichen Preise der Claude Opus 4.6 API auf Kie.ai kennenlernen.
Integrieren Sie die Claude Opus 4.6 API in Ihre Anwendung
Verbinden Sie nach dem Test im Playground die Claude Opus 4.6 API mit Ihrer eigenen Anwendung oder Ihrem Workflow. Nutzen Sie Ihren API-Key, um Anfragen direkt aus Ihrem Backend, Ihrer Toolchain oder internen Plattform zu senden, und beginnen Sie damit, das Modell in reale Produktlogik einzubinden. So werden aus ersten Experimenten auf Kie.ai funktionierende Implementierungen für Chat-, Coding-, Dokumenten- oder Agenten-Anwendungsfälle.
Konfigurieren Sie die Claude Opus 4.6 API für Produktions-Workloads
Sobald die Basis steht, machen Sie Ihr Setup fit für die Produktion. Optimieren Sie die Request-Struktur, verfeinern Sie Prompts für stabilere Ergebnisse und passen Sie die Nutzung an Komplexität, Latenz und Kostenerwartungen an. So wird die Claude Opus 4.6 API zur praktischen Lösung für den langfristigen Einsatz statt nur für einmalige Tests.
Claude Opus 4.6 API skalierbar deployen mit Kie.ai
Sobald der Workflow sitzt, gehen Sie mit der Claude Opus 4.6 API live. In dieser Phase weiten Teams die Nutzung typischerweise auf kundenorientierte Produkte, interne Automatisierung, Forschung oder Coding-Tools aus. Mit Kie.ai ist der Weg vom Test über die Integration zum Deployment direkter – so können Sie die günstigen Preise der Claude Opus 4.6 API im echten Einsatz besser einschätzen.
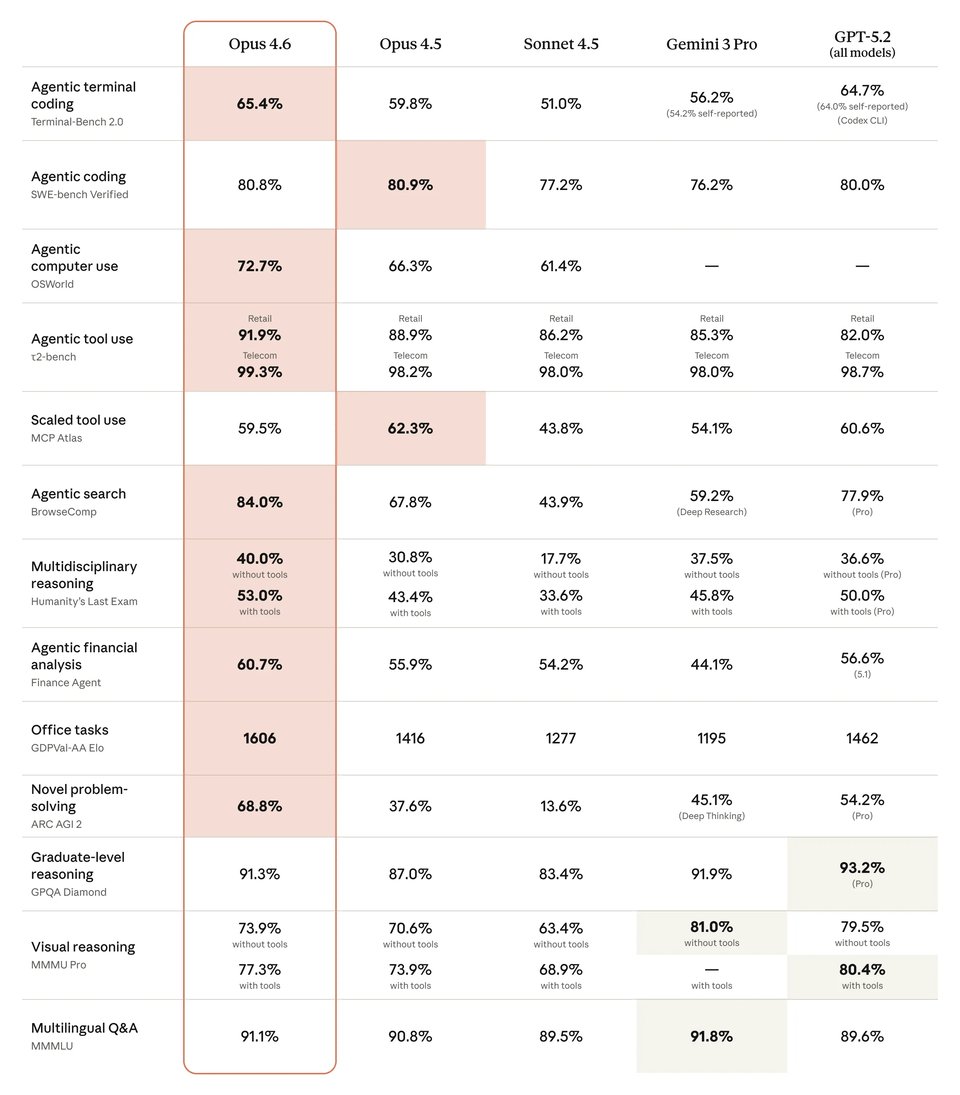
Claude Opus 4.6 im Vergleich zu Gemini 3.1 Pro, GPT-5.4 und anderen Claude-Modellen
Claude Opus 4.6 zeigt ein starkes Benchmark-Profil in den Bereichen Coding, Computersteuerung, Suche und fortgeschrittenes Reasoning im Vergleich zu Gemini 3.1 Pro, GPT-5.4 und früheren Claude-Modellen. Der folgende Vergleich zeigt: Claude Opus 4.6 führt bei mehreren wichtigen Workflow-Benchmarks deutlich gegenüber Claude Opus 4.5, Claude Sonnet 4.5 und Gemini 3.1 Pro, während GPT-5.4 in Bereichen wie Terminal-Coding, Computersteuerung und Reasoning auf akademischem Niveau äußerst konkurrenzfähig bleibt. Dies macht Claude Opus 4.6 zu einer überzeugenden Wahl für Teams, die die Modellleistung für agentenbasierte Aufgaben und produktionsorientierte Wissensarbeit bewerten.
| Benchmark | Claude Opus 4.6 | Claude Opus 4.5 | Claude Sonnet 4.5 | Gemini 3.1 Pro | GPT-5.4 |
|---|---|---|---|---|---|
| Agentic terminal coding | 65.40% | 59.80% | 51.00% | 68.50% | 75.10% |
| Agentic computer use | 72.70% | 66.30% | 61.40% | — | 75.00% |
| Agentic search | 84.00% | 67.80% | 43.90% | 85.90% | 82.70% |
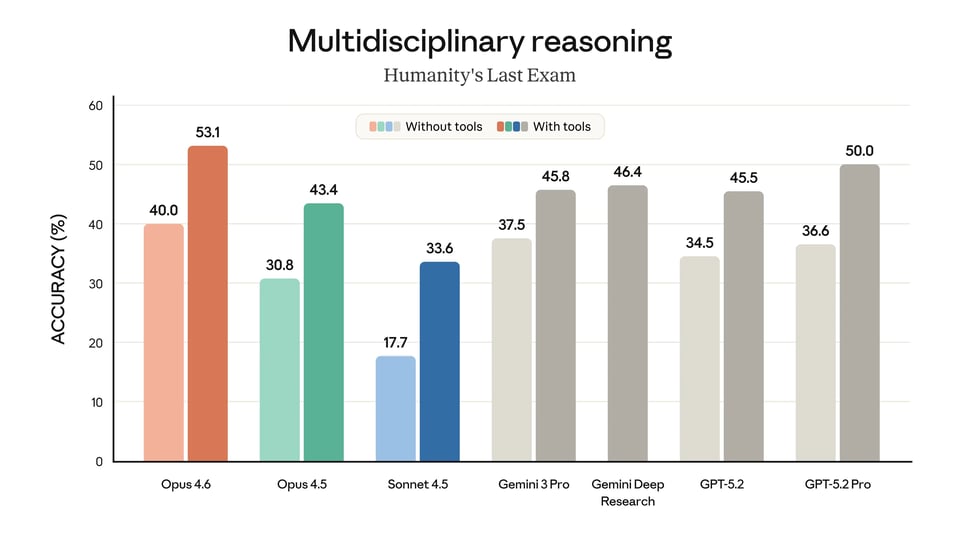
| Multidisciplinary reasoning (no tools) | 40.00% | 30.80% | 17.70% | 44.70% | 39.80% |
| Multidisciplinary reasoning (with tools) | 53.00% | 43.40% | 33.60% | — | 52.10% |
| Graduate-level reasoning | 91.30% | 87.00% | 83.40% | 94.30% | 92.80% |