Automatically append previous messages to maintain multi-turn context. May increase token usage.
How can I help you today?
Affordable Claude Opus 4.6 API On Kie.ai
Access Anthropic Claude Opus 4.6 API on Kie.ai for coding, reasoning, and long-context workflows with more affordable deployment.

What’s New in Anthropic Claude Opus 4.6 API
Stronger Coding, Debugging, and Code Review in Claude Opus 4.6 API
Claude Opus 4.6 API delivers a clear upgrade in software engineering performance. It handles coding tasks with better planning, improves debugging accuracy, and performs code review more reliably across larger and more complex codebases. Compared with earlier Opus models, Claude Opus 4.6 API is better at catching mistakes, revisiting its reasoning, and sustaining quality through multi-step development workflows.
1M Token Context Window for Claude Opus 4.6 API
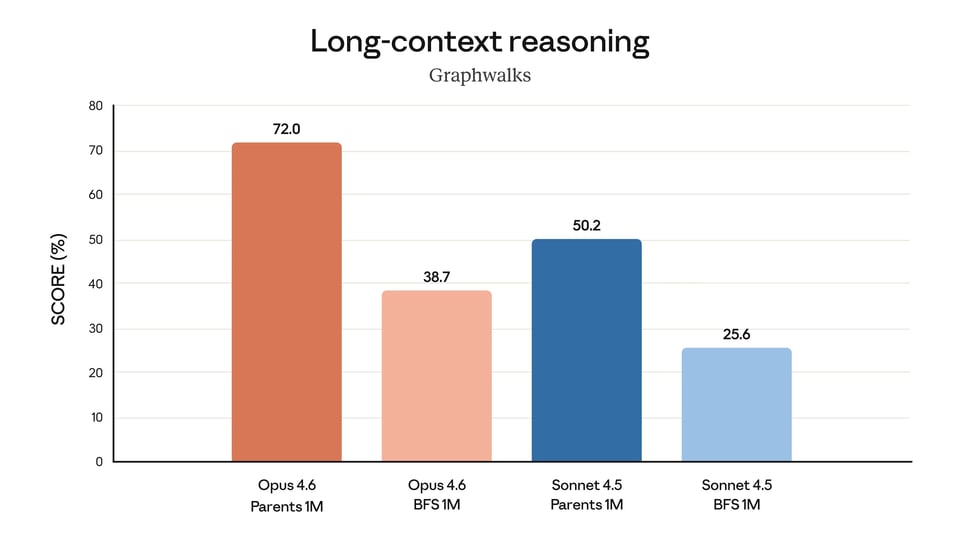
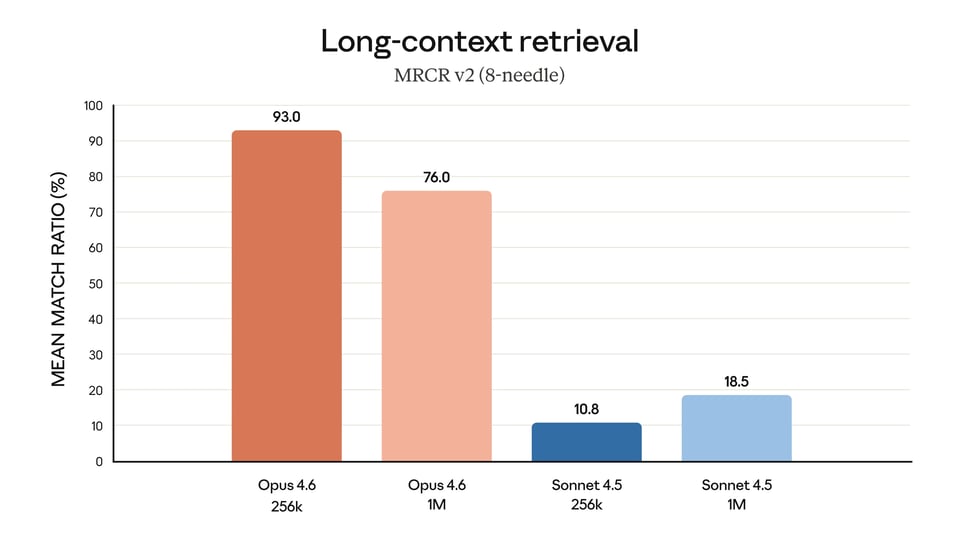
One of the biggest updates in Claude Opus 4.6 API is the introduction of a 1M token context window in beta. This gives Claude Opus 4.6 API a much stronger foundation for long-document processing, large-context retrieval, and extended reasoning over dense inputs. It is designed to reduce context drift and improve performance on tasks that require tracking information across very large amounts of text.
Adaptive Thinking, Effort Controls, and Context Compaction in Claude Opus 4.6 API
Claude Opus 4.6 API adds several new controls that make the model more practical for production use. Adaptive thinking allows Claude Opus 4.6 API to apply deeper reasoning when needed, while effort controls give developers more flexibility to balance intelligence, latency, and cost. Context compaction further helps Claude Opus 4.6 API support longer-running conversations and agentic workflows by summarizing older context before limits are reached.
128k Output Tokens Expand Claude Opus 4.6 API for Larger Tasks
Claude Opus 4.6 API supports outputs of up to 128k tokens, making it better suited for tasks that require larger responses in a single run. This is especially useful for long-form generation, large code transformations, structured document outputs, and other workflows that would otherwise need to be split across multiple requests. With higher output capacity, Claude Opus 4.6 API becomes more practical for applications that need longer and more complete outputs.
How to Deploy with Affordable Claude Opus 4.6 API Pricing on Kie.ai
Get started with our product in just a few simple steps...
Sign Up on Kie.ai and Get Your Claude Opus 4.6 API Key
Create your Kie.ai account first to access the Claude Opus 4.6 API. Once registered, you can generate your API key from the dashboard and prepare your environment for integration. This gives you a direct starting point for testing requests, authenticating API calls, and building with Claude Opus 4.6 API in a more developer-friendly workflow.
Test Claude Opus 4.6 API Free in the Playground
Before moving into development, use the playground to try Claude Opus 4.6 API for free. This is the fastest way to evaluate response quality, explore prompt behavior, and understand how the model performs on coding, long-context, reasoning, or agent-style tasks. It also helps teams validate use cases early while exploring affordable Claude Opus 4.6 API pricing through Kie.ai.
Integrate Claude Opus 4.6 API into Your Application
After testing in the playground, connect Claude Opus 4.6 API to your own application or workflow. Use your API key to send requests from your backend, toolchain, or internal platform, then start building the model into real product logic. This step turns early experimentation on Kie.ai into a working implementation for chat, coding, document, or agentic use cases.
Configure Claude Opus 4.6 API for Production Workloads
Once the basic integration is running, adjust your implementation for production needs. Set the right request structure, refine prompts for more stable outputs, and optimize usage based on task complexity, latency, and cost expectations. This makes Claude Opus 4.6 API more practical for long-term deployment instead of simple one-off testing.
Deploy Claude Opus 4.6 API at Scale with Kie.ai
When your workflow is validated, move Claude Opus 4.6 API into full deployment. At this stage, teams typically expand usage across customer-facing products, internal automation systems, research workflows, or code-related tools. With Kie.ai, the path from testing to integration to deployment is more direct, making affordable Claude Opus 4.6 API pricing easier to evaluate in real production scenarios.
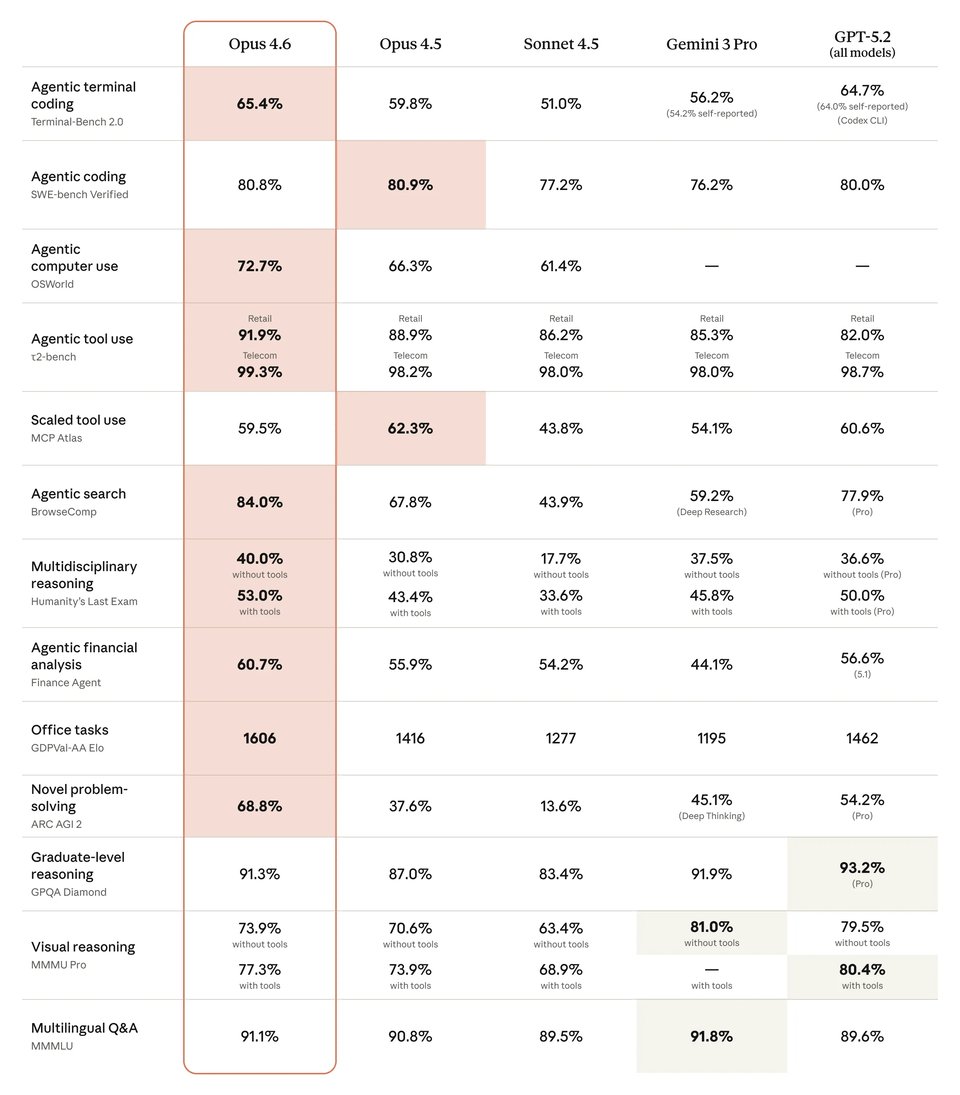
Claude Opus 4.6 vs Gemini 3.1 Pro, GPT-5.4, and Other Claude Models
Claude Opus 4.6 shows a strong benchmark profile across coding, computer use, search, and advanced reasoning when compared with Gemini 3.1 Pro, GPT-5.4, and earlier Claude models. In the comparison below, Claude Opus 4.6 leads clearly over Claude Opus 4.5, Claude Sonnet 4.5, and Gemini 3.1 Pro on several high-value workflow benchmarks, while GPT-5.4 remains highly competitive in areas such as terminal coding, computer use, and graduate-level reasoning. This makes Claude Opus 4.6 a compelling choice for teams evaluating model performance across both agentic tasks and production-oriented knowledge work.
| Benchmark | Claude Opus 4.6 | Claude Opus 4.5 | Claude Sonnet 4.5 | Gemini 3.1 Pro | GPT-5.4 |
|---|---|---|---|---|---|
| Agentic terminal coding | 65.40% | 59.80% | 51.00% | 68.50% | 75.10% |
| Agentic computer use | 72.70% | 66.30% | 61.40% | — | 75.00% |
| Agentic search | 84.00% | 67.80% | 43.90% | 85.90% | 82.70% |
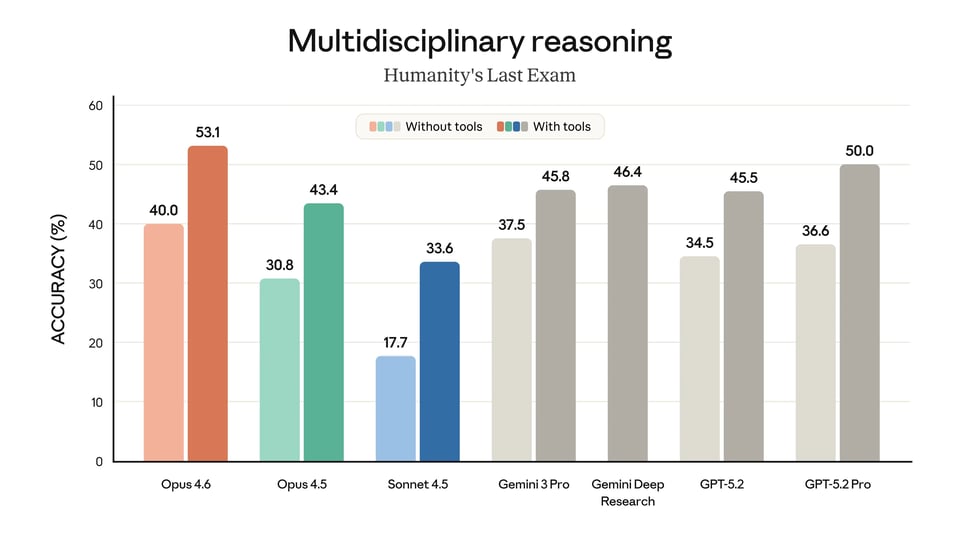
| Multidisciplinary reasoning (no tools) | 40.00% | 30.80% | 17.70% | 44.70% | 39.80% |
| Multidisciplinary reasoning (with tools) | 53.00% | 43.40% | 33.60% | — | 52.10% |
| Graduate-level reasoning | 91.30% | 87.00% | 83.40% | 94.30% | 92.80% |